
Authzed builds SpiceDB, an open source fine-grained permissions database inspired by Google's Zanzibar paper. In addition to developing SpiceDB, we also operate managed SpiceDB services: fully isolated, dedicated clusters or permission systems in our Serverless platform. The SpiceDB serverless platform is powered by CockroachDB, which fulfills the role played by Spanner in the paper: it's the foundation that makes it possible to run geographically distributed workloads with linearizable consistency to prevent the new-enemy problem.
In this post we are discussing database connection draining, a topic often overlooked but has an impact on your application availability. We will answer:
- Why are database connections so important?
- What is connection draining?
- How does it affect application availability?
- How to properly handle it?
- Example: connection draining in CockroachDB
The example will be focused on Go applications and CockroachDB in particular, but the fundamentals are equivalent in other programming languages and database vendors.
Connection draining is also not exclusive to databases: any backend system running in modern infrastructure should also handle it.
Why are database connections so important?
Applications perform operations on databases over a connection: they are the "pipe" over which applications "talk" to DBs and so are a critical part of such interactions.
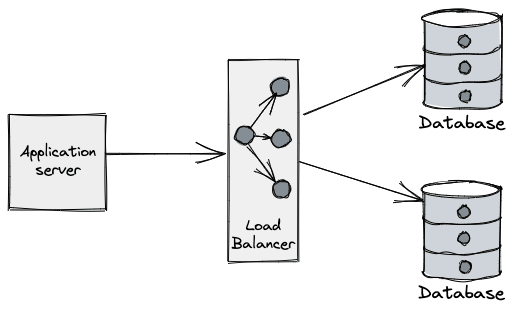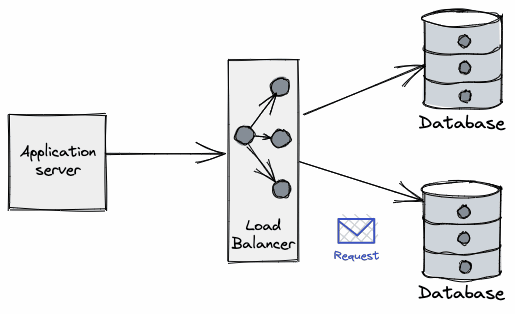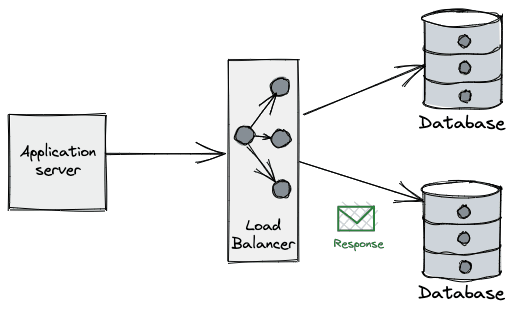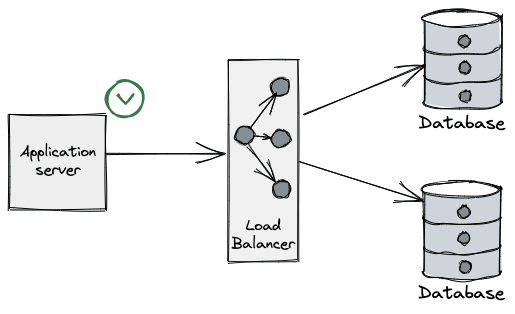
Connections are typically a limited (and scarce) resource - most databases have a default connection limit on how many can be opened at a given time, usually due not only the network sockets required, but also the database’s own connection management overhead. Having a large number of connections opened may affect the performance of the database, which can see its throughput reduced as the number of connections grows.
The process of opening a new database connection is often not cheap either, mainly due to network latency, TCP/TLS handshake, etc. When combined with the aforementioned limits, developers are forced to come up with clever tricks to amortize time spent on the lifecycle of the connection and make more efficient use of those already established.
Connection pooling is a well-known strategy where clients "lease" connections to perform an operation and return it to the pool as soon as they are done. The demand to make efficient use of connections is so common that some proxies have emerged to offload this responsibility from client applications, like ProxySQL for MySQL or PgBouncer for Postgres.
It turns out that handling connections in client applications is not trivial. When applications don’t do connection pooling:
- Their performance will be affected due to the inherent connection lifecycle overhead.
- The application can impact the database load, throughput, and likely availability by overloading it with connections.
On the other hand, while connection pooling can mitigate these problems, it comes with its own set of challenges:
- Application threads may have to "wait in line" for a connection to become available, which increases request time and reduces throughput.
- The application/pooler implementation needs to ensure connections in the pool are still established and healthy, otherwise, client applications may end up picking a stale connection, which causes errors if unhandled, or requires non-trivial error recovery logic and retries.
Unsurprisingly, a lot of energy is spent on properly handling database connections. The goal of this post is not to define the ultimate "how-to database connection guide" (you'll have to look elsewhere for that!) but to focus on a particular segment of this complex topic that does not get enough attention: connection draining.
What is connection draining?
Databases are not systems that you spin up and forget about:
- The underlying operating system may need an update.
- A critical CVE fix may involve updating the database version.
- Application growth driven by customer demand may involve vertical scaling, and for that, we need to move it to a new rack with more CPU cores and/or memory.
These are just some examples. The gist is that the database process will eventually need to be terminated. So what does the DB do about all its precious connections upon termination?
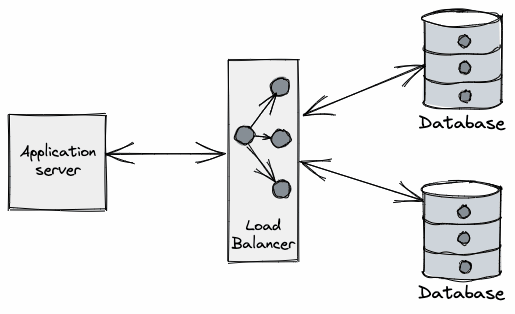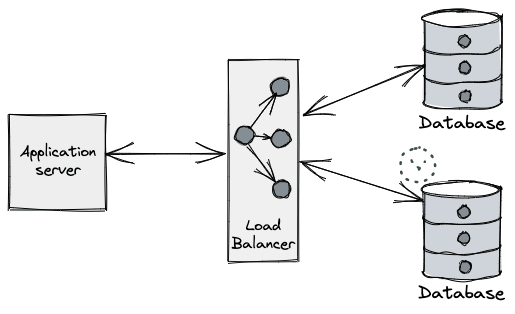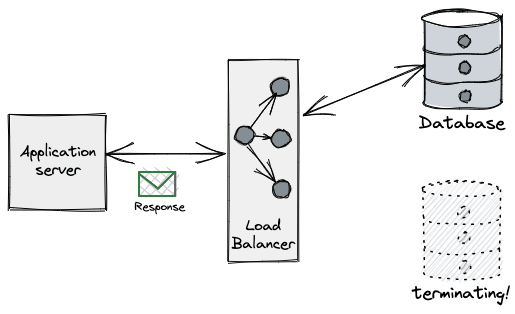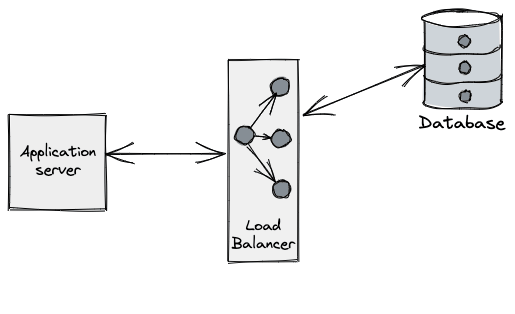
Databases typically implement some sort of connection-draining phase during termination. This is a procedure put in place to allow client applications to gracefully handle these connections getting closed by the server. This grace period is needed because database communication protocols laid over TCP/IP are generally frontend-initiated (e.g. Postgres spec), and the full-duplex nature of TCP means one side of the connection may be closed while the other remains open, unknowingly to the other side. The great Vicent Martí wrote at length about the perils of the database connection lifecycle when using the Go MySQL driver.
How connection draining works varies across vendors, but it typically involves the same phases:
- Let load-balancers know the process is unready (usually via a health check).
- This makes load-balancers stop funneling new connections to the backend database node.
- Stop accepting new database connections.
- Let in-flight requests complete.
- Give a grace period for the client to close connections or forcefully close them server-side after a deadline.
Fortunately for us, CockroachDB offers an exemplary connection-draining procedure described in their docs.
How does it affect application availability?
Ignoring database connection draining procedures is a fairly common source of availability issues. Depending on the nature of the workload, problems may include intermittent errors, small blips in availability, the system being partially unavailable, and breaching SLOs.
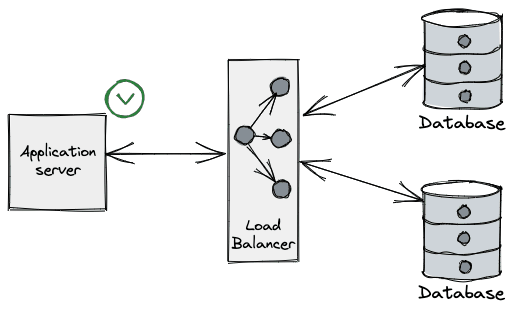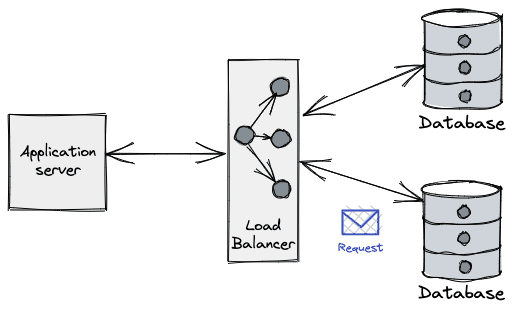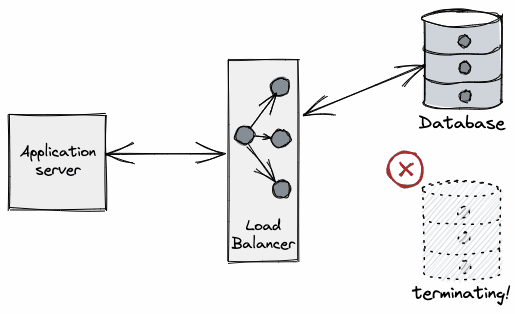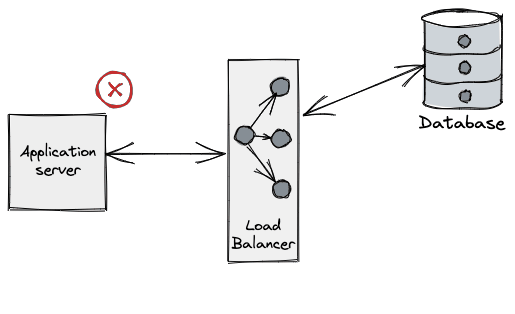
From the application perspective what we typically see is an error when performing a query on a connection. (e.g. unexpected EOF in Go), even on a freshly leased connection.
This can make the situation quickly snowball:
- Request latency spikes and stalls as the application builds contention over the connection pool.
- Requests becoming slower may lead to clients retrying and make the situation worse.
- The database can get saturated due to the spike in connection attempts.
- The application can also get saturated, fail to respond to health checks, and get terminated by workload schedulers like Kubernetes, which in turn puts more pressure on the remainder of the replicas.
Depending on the environment, connection draining can be relatively frequent, and these intermittent problems may start to eat up our error budget.
How to properly handle it?
The first step is to look into your database instance configuration and determine what the connection drain timeout is. This parameter is the grace period databases give clients before starting to forcefully close connections, and it could be one or multiple knobs.
Load balancers also need to be taken into consideration, as being part of the request path also means they play a role in connection draining. Whether you are running your own load balancers like HAProxy or a managed service like those offered by the likes of AWS, Azure or GCP, a drain timeout parameter will be most likely available. The timeout starts to count when the load-balancer recognizes the backend is unhealthy, after which it will stop forwarding new requests and will let any in-flight request complete for the duration of the timeout before forcefully closing them.
Naturally, both the load-balancer and backend drain timeout must be aligned: the drain timeout of the backend database should not exceed that of the load-balancer, or the latter may prematurely terminate connections while the backend is still draining.
Defining the drain timeout is an exercise of balance, as there is no single value that works for every application:
- A large drain timeout would affect the velocity to roll out changes to a database cluster. Imagine a critical OS upgrade that needs to be rolled out promptly to hundreds of database clusters: a 30 minutes drain could mean the upgrade would take days to complete.
- A short drain timeout means high connection churn and additional overhead. This could affect tail latencies for your application, where some requests could be spending more time in connection management than in the business logic itself.
From the application-developer perspective, you probably want to favor a large drain timeout, but you’ll also likely have to dial it back depending on the limitations of the DBaaS of your choice, or requirements imposed by your database team.
Once you’ve settled on a connection drain value, you’ll need to configure your application’s database driver/pooler of choice.
Most mature implementations out there offer such APIs, like Go’s DB.SetConnMaxLifetime which is part of the standard database/sql package.
You will want to validate your configuration in production by running a database connection draining procedure drill. This is not always possible (e.g. managed databases that do not offer this option) so you may have to wait until the next update (bummer!) or run a simulation in a local environment. For example, you could set up a docker-compose configuration that spins up several replicas of a database along your application and simulate the process by running the draining process inside the container. We did exactly this to validate our drain configuration locally and you can find it in our examples repository.
Example: Connection Draining in CockroachDB
In CockroachDB connection draining is handled by multiple parameters that configure the duration of the different phases of the drain procedure. Cockroach Labs offers excellent documentation on the topic, so definitely check it out.
server.shutdown.drain_waitis the parameter used to have CRDB nodes cooperate with the load-balancer. It marks the node as unhealthy so the LB stops sending requestsserver.shutdown.connection_waitis the actual connection drain timeout and the value you should set your driver/pool max connection lifetime to. It is a relatively recent addition to CRDB, only available from CRDB 22.X, so you may need to update your clusters.- If your application hasn’t closed connections during connection_wait, CRDB will wait up to
server.shutdown.query_waitfor those queries to complete before forcefully closing them. Ideally, the application would have closed all connections by itself before we reach this phase.
One may be tempted to set these to a relatively large value for the reasons discussed earlier, but there is a catch: the whole drain procedure must not exceed the drain timeout. This value hasn’t been well documented until recently and largely depends on how CRDB is operated. For Cockroach Dedicated, this limit is 5 minutes and is not configurable. If the sum of the various parameters takes longer than that chances are ungraceful connection termination will happen.
In Go we should set DB.SetConnMaxLifetime to a value less than the configured drain timeout, specifically the value chosen for connection_wait.
And it is important that the sum of all parameters never exceeds the global drain timeout limit.
The recommendation is:
SetConnMaxLifetime < server.shutdown.connection_wait < sum(server.shutdown.*) < drain timeout limit
A few things to note:
- The defaults are most likely not what your application needs, so make sure to set values for the 3 drain parameters. Some of those parameters default to zero.
- If you are using jackc/pgx, make sure to always end statements with commit/rollback, otherwise connections will not be released to the pool and will never get closed even if they have exceeded the max lifetime.
- jackc/pgx health check may help with transients, but you can’t guarantee they are evaluated when you need them. A more effective strategy is to introduce application-side retries, like what we see in the cockroach-go module.
We’ve experimented with different values and we found the sweet spot for our production workloads was:
drain_wait 30s
connection_wait 4m
query_wait 10s
The above configuration gives Cockroach Labs managed load-balancers a generous 30s to react to nodes being marked as unhealthy.
Given the upper boundary of 5m, we assigned most of the weight of the "drain budget" available to connection_wait and made sure to leave some padding (the sum of the three flags is less than 5m).
Finally, we configured SpiceDB with the flags that control SetConnMaxLifetime and SetConnMaxIdleTime (datastoreConnMaxLifetime and datastoreConnMaxIdletime, respectively) to the value of connection_wait, in this case, 4m.
Remember to test the draining process. Cockroach Labs unfortunately does not offer a means to drain your dedicated Cockroach instances, so we had to rely on simulations in our local environments via the aforementioned docker-compose example, and in our stage environment where we operate our own CRDB cluster using their opensource Kubernetes operator. This worked for the most part, except for misleading documentation of the global drain limit of 5m which has been recently fixed in the docs.
Have a question? Check out the Discord, where we and the community are discussing all things SpiceDB
Additional Reading
If you’re interested in learning more about Authorization and Google Zanzibar, we recommend reading the following posts: