
Anatomy of a Cache Entry
In section 3.2.5 of Google's Zanzibar paper, the authors say: "We found the handling of hot spots to be the most critical frontier in our pursuit of low latency and high availability." They go on to describe a system of splitting peer Zanzibar servers into a distributed cache where the cache keys include an evaluation timestamp and servers are selected based on consistent hashing. With SpiceDB, AuthZed's open-source Google Zanzibar implementation, we've created a faithful implementation of this system. In today's blog post, I want to talk about how this all works under the hood.
"We found the handling of hot spots to be the most critical frontier in our pursuit of low latency and high availability."
Section 3.2.5, Zanzibar: Google's Consistent, Global Authorization System
You may recall in our Check it Out #2 blog post, Joey demonstrated how we can break down top-level problems into subproblems to make caching easier.
For a quick refresher, consider the following schema and relationships:
definition user {}
definition organization {
relation admin: user
}
definition document {
relation org: organization
relation owner: user
relation reader: user
permission view = reader + owner + org->admin
}
document:doc1hasorgoforganization:org1
document:doc1hasownerofuser:sally
document:doc1hasreaderofuser:billy
organization:org1hasadminofuser:francesca
When evaluating the top level question: "Can user:francesca view document:doc1?", there are several interesting subproblems:
"Is user:francesca reader of document:doc1?"
"Is user:francesca owner of document:doc1?"
"document:doc1 has org of organization:org1. Is user:francesca admin of organization:org1?"
In Zanzibar, in order to return consistent results, all problems are evaluated at a consistent snapshot timestamp. You can think of these as representing a single moment in time. If we pick an example timestamp 12345, this becomes an implicit clause for our top-level problem and all sub-problems:
"Can user:francesca view document:doc1 at timestamp 12345?"
"Is user:francesca reader of document:doc1 at timestamp 12345?"
And so on.
Ignoring SpiceDB Caveats for a moment, each of these questions also has a yes or no answer at any given time. In SpiceDB, we refer to this answer as "permissionship", with values: PERMISSIONSHIP_HAS_PERMISSION and PERMISSIONSHIP_NO_PERMISSION respectively.
For any given problem or sub-problem, at a specified time, the result to the check is **immutable**: the value will not ever change. Here are the immutable answers to the problems and sub-problems from above:
"Is user:francesca reader of document:doc1@ 12345?"→ PERMISSIONSHIP_NO_PERMISSION
"Is user:francesca owner of document:doc1@ 12345?" → PERMISSIONSHIP_NO_PERMISSION
"document:doc1 has org of organization:org1. Is user:francesca admin of organization:org1@ 12345?" → PERMISSIONSHIP_HAS_PERMISSION
"Can user:francesca view document:doc1 @ 12345?" → PERMISSIONSHIP_HAS_PERMISSION
These become cache keys in SpiceDB as follows:
document:doc1#reader@user:francesca@12345 → PERMISSIONSHIP_NO_PERMISSION
document:doc1#owner@user:francesca@12345 → PERMISSIONSHIP_NO_PERMISSION
organization:org1#admin@user:francesca@12345 → PERMISSIONSHIP_HAS_PERMISSION
document:doc1#reader@user:francesca@12345 → PERMISSIONSHIP_HAS_PERMISSION
It is important to note: if we were to change the evaluation timestamp, the cache keys would change as well and the existing answers would become irrelevant. That is why picking evaluation timestamps becomes so important.
Picking a Good Snapshot Timestamp
In the previous section, I said that a timestamp represents a single unique point in time. While there is some debate about whether the passage of time is actually an illusion, for our lived experience a single instant of time occurs only once, and if we were randomly picking times, we would have an infinitesimally small chance of picking the exact same time twice. So how do snapshots timestamps help us?
To make this easier to visualize, we will use the following diagram of a timeline:
On the X-axis we have a time continuum from 0 to 10, and on the Y-axis we have the snapshot timestamp that the request was actually evaluated at. In this example our request was sent at time 5, and the snapshot timestamp chosen was also time 5.
There are several important factors that play together when determining the timestamp at which a problem and all of its subproblems will be evaluated. The most important of these factors though is the user's specified consistency level.
SpiceDB allows you to choose amongst four levels of consistency on a per-request basis:
| fully_consistent | Chooses the system's current time as the snapshot timestamp, and will include all changes that were fully committed before the request was started. |
| snapshot | Evaluates requests at the exact same timestamp as that encoded in a ZedToken from a previous request. |
| minimize_latency | Allows the system to freely choose a timestamp that balances freshness while also minimizing latency. |
| at_least_as_fresh | Allows the system to choose a timestamp, as long as the time selected occurs after the time represented in the user-supplied ZedToken. |
Fully Consistent
At consistency level fully_consistent we are always picking the exact snapshot timestamp at which the request arrived at the system. Here is an example with many requests and the snapshot timestamp chosen.
As you can see, no two requests are evaluated at the same snapshot timestamp, effectively disabling the cache.
At Exact Snapshot
At consistency level at_exact_snapshot we are always picking the same snapshot revision for every request. This will result in perfect cache usage, but our results will get more and more stale as time goes on.
In this example, the default setting for the Snapshot Revision is 4.25s and all of our requests are evaluated at that time. By the time we get to time 10 our results are already 5.75 seconds old. You can further adjust the Snapshot Revision setting and observe how the average staleness of results changes.
Minimize Latency
At consistency level minimize_latency we allow the server to pick a snapshot timestamp freely to optimize the experience. We use quantization, a method to downsample high-frequency data into discrete buckets, to allow different servers to all choose the same request timestamps independently. In this example, the server is configured with --datastore-revision-quantization-interval=1s (the default is 5s) and --datastore-revision-quantization-max-staleness-percent=0.
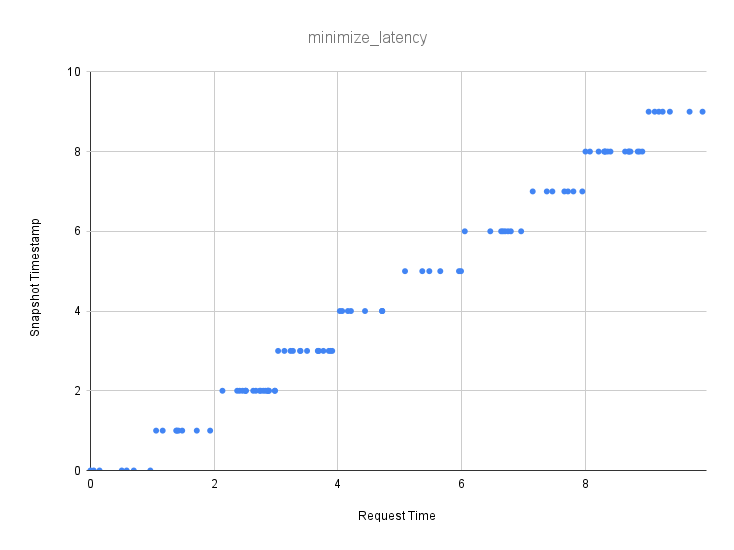
As you can see, the request times are quantized (i.e. rounded) down to the nearest whole second. This lets us re-use cache entries for as many requests are we receive during that 1s window, and our results will be up to 1s stale. This allows us to make an intentional tradeoff between consistency and cache usage.
In order to avoid effectively completely evicting the cache every time a new quantization period starts, Pull Request #1285 introduced the ability to blend between one quantized revision and the next over a period of allowed staleness. The following example shows a staleness of 100% of the quantized revision, i.e. 1s:
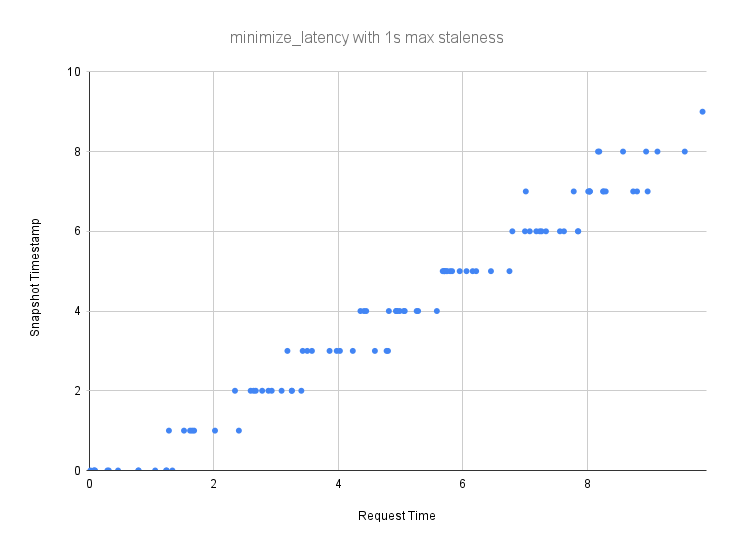
As you can see, there are multiple active candidate snapshots at every request time. Older snapshot revisions are phased out and newer snapshot revisions are phased in. We can visualize this probability as a stacked area chart, where all probabilities always add up to 100%. Here is such a chart for 1s max staleness:
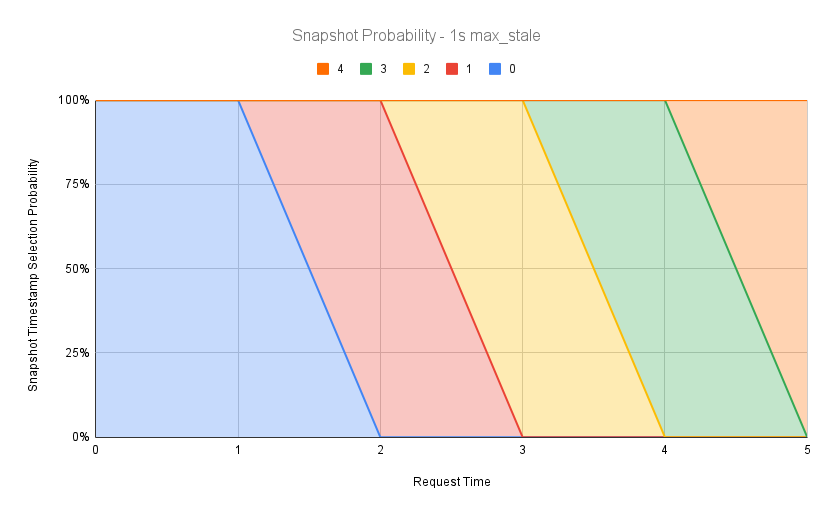
We can adjust the staleness time according to our requirements for freshness of answers, even beyond 100%. The following graphs demonstrate 10% (0.1s) and 200% (2s) of max staleness respectively:
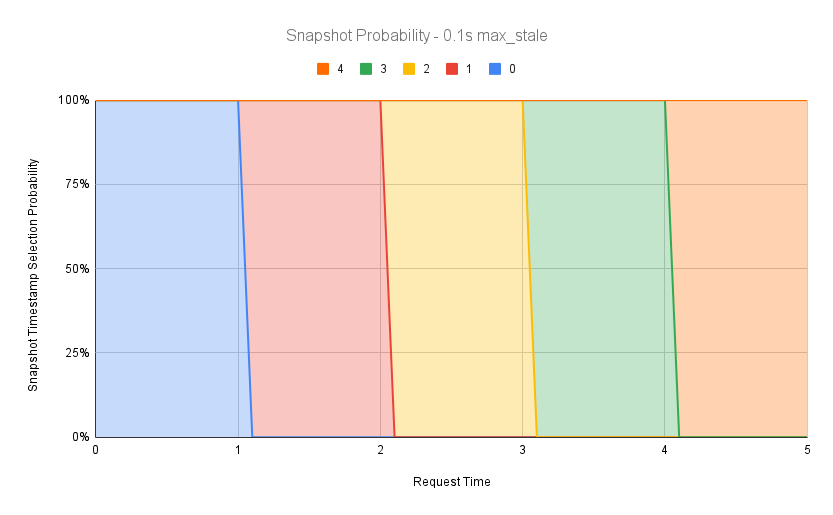
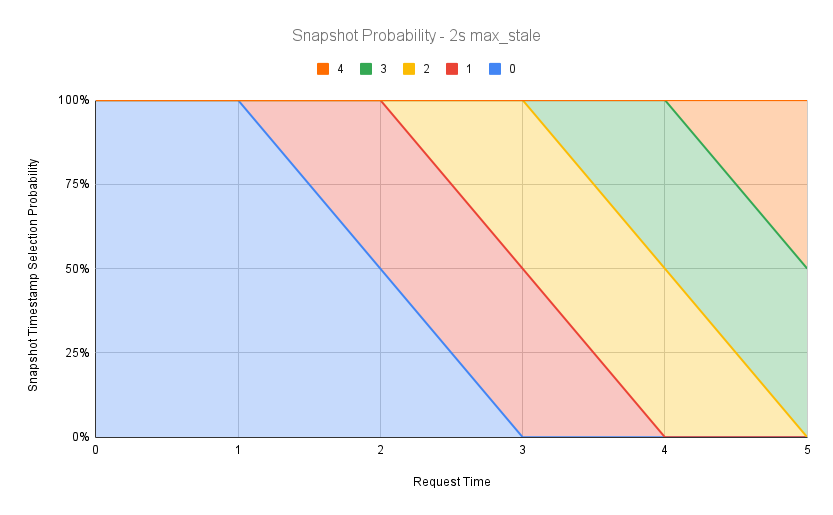
Play with the Quantization Window and Max Stale Percentage settings to see how they affect snapshot revision reuse and result staleness.
At Least as Fresh
At consistency level at_least_as_fresh we use ZedTokens (Zookies in the Zanzibar paper) to give the user a powerful way to express causality between requests in the system. Functionally, you can think of an at_least_as_fresh request as being the same as minimize_latency unless the selected timestamp is less than the timestamp encoded in the ZedToken. When that happens, the chosen timestamp is adjusted forward to use the timestamp encoded in the ZedToken. In our scatterplot visualizations this looks like the following:
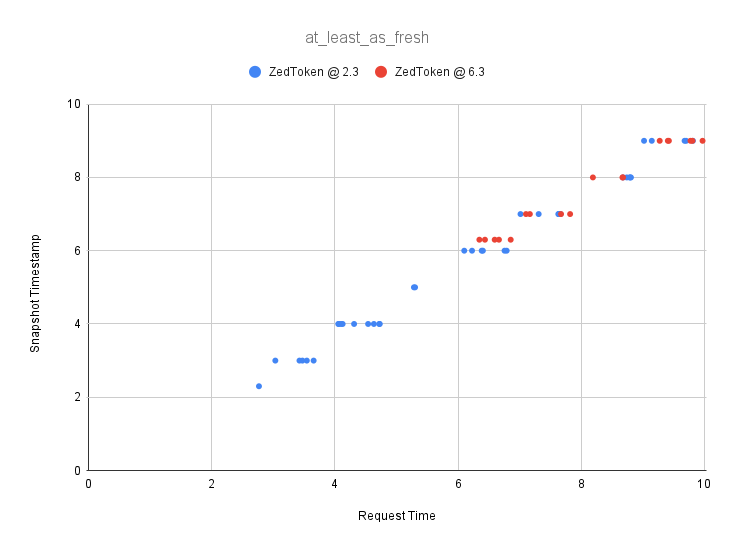
We see the familiar stepped pattern from minimize_latency. However, when a request is received in between the ZedToken being issued and the next quantized revision, it is adjusted as seen in the following zoomed scatterplot when a request comes in between times 6.3 and 7 with the ZedToken at time 6.3:
.png)
Adjust the settings in the following interactive chart and observe the effect on the timestamps.
Allowing a user to pick their consistency level means that SpiceDB is usually picking revisions using all of these modes at the same time, with each request making the appropriate tradeoff between consistency, freshness, and performance.
Now that we see how the system as a whole creates and utilizes immutable cache entries, let's see how we scale it!
Consistent Hashring Dispatch
The Zanzibar paper Section 3.2.5 (that we referenced earlier) has this to say about scaling this caching solution:
Zanzibar servers in each cluster form a distributed cache for both reads and check evaluations, including intermediate check results evaluated during pointer chasing. Cache entries are distributed across Zanzibar servers with consistent hashing.
Evan, one of our engineers, has written about the "how" for consistent hash load balancing before in his post: Consistent Hash Load Balancing for gRPC, but I would like to expand a little bit more on the "why".
It's simple math really: if all nodes were equally likely to compute (and cache) the results for every problem and subproblem, we would end up storing several copies of the same result. If our average cache result size is B bytes, and we've dedicated M bytes of memory on each server to caching, the total number of unique problems we can keep in cache (regardless of cluster size) is M / B. Additionally, our cache hit ratio will suffer due to needing to recompute each cache entry on each server the first time that problem or sub-problem is encountered.
If we were to always send the same problem or sub-problem to the same SpiceDB server or group of servers, we could achieve higher hit rates, and more overall caching. If we sent each problem to only one server, our overall number of unique cached items in a cluster of size N would be N * M / B. Thus, as our dataset grows, we can keep more of it in cache by expanding our cluster size correspondingly.
Hotspot Caching vs. Other Types of Caching
The type of caching we've discussed in this post, hotspot caching, is used to address latency problems when the same data is accessed frequently. There are other types of caching referenced in the Zanzibar paper as well. Section 3.2.5 also describes a relationship cache where groups of frequently accessed relationships are cached, and Section 3.2.4 describes the "Leopard Indexing System", which is a continually updated denormalization of user group data stored in Zanzibar. Lovingly following the CPU cache naming model, we refer to these techniques internally as L0 and L2 caches, and have designs for how these will make their way into SpiceDB in the future.
But that's a story for another time.
Sincerely, Your Most Faithful Implementation
I hope this has been an informative post, and that you've learned a lot about our implementation of hotspot caching in SpiceDB. If you're using one of AuthZed's hosted SpiceDB solutions, you're already taking advantage of hotspot caching automatically. If you're one of our self-hosted or open source customers, I hope you've learned enough about how the various datastore parameters and consistency levels work together to tailor your experience. If you'd like to learn more, you can reach us through our Discord, by scheduling a call, or by reaching out to support@authzed.com.
Additional Reading
- AuthZed's Annotated Google Zanzibar Paper
- Consistent Hash Load Balancing for gRPC
- The Architecture of SpiceDB
- What is Google Zanzibar
Image Credit: NASA Goddard Space Flight Center, CC BY 2.0, via Wikimedia Commons
{kind=link}