
Update: The LangChain - SpiceDB library is now an official integration
AI apps are no longer a skunkworks project in the corner of an engineering org. RAG pipelines, LLM-powered agents, and multi-step assistants are running in production at companies of all sizes — and LangChain has become the de facto framework for building them. It's opinionated enough to get you moving fast, and popular enough that "we're using LangChain" needs no further explanation to any developer in the room.
But there's a problem LangChain doesn't solve for you: authorization. In the AI agent world, this is genuinely tricky.
For a traditional web app, access control is fairly contained — you're deciding who can click a button or hit an API endpoint. For an AI agent doing retrieval, the surface area explodes. An agent might pull from hundreds of documents in a single query. Users have different permission levels on different resources. And the LLM doesn't know any of this — it just answers. A junior associate asks your internal AI assistant about client litigation strategy. The semantic search retrieves exactly the right documents — including a partner-only strategy memo. The LLM gives a perfect answer. Congratulations: your data has just been breached.
Relationship-Based Access Control (ReBAC) is the right model here — not RBAC, which is too coarse for this problem. In 2019, Google published the Zanzibar paper, laying out the authorization system behind Drive, Calendar, and Docs. The core insight: permissions aren't about roles, they're about relationships — does this user have view access on this specific document given their relationship to it? SpiceDB is the open-source implementation of that system.
Enter langchain-spicedb — a library that brings SpiceDB's authorization model into LangChain and LangGraph workflows, so you can build RAG pipelines that actually respect what users are allowed to see.
Most RAG pipelines treat retrieval as a pure semantic problem
Here's the standard RAG flow:
User asks a question → you embed it → you fetch the closest vectors → you hand those documents to an LLM → the LLM answers.
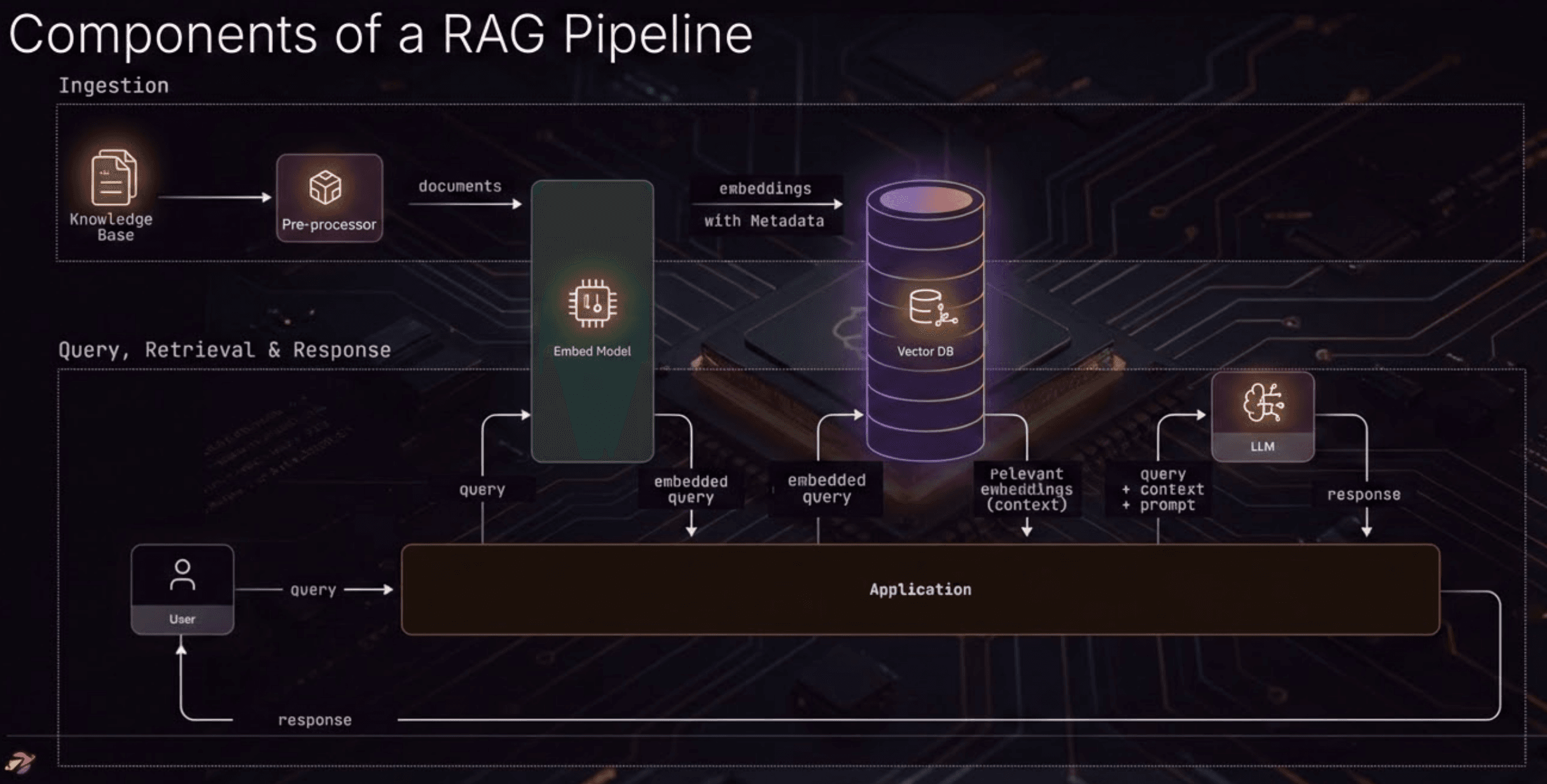
Nowhere in this flow is there a step that asks: does this user actually have permission to see these documents?
When authorization does get added, it usually arrives as RBAC: "this user has the employee role, employees can read public documents." Simple, but inadequate for anything involving multiple users with relationships to specific resources.
RBAC works fine when you're guarding a menu item or an API endpoint — "only admins can see the billing page" is a perfectly reasonable use of a role. But real documents don't work that way. A legal memo belongs to a specific matter. A sales deck is shared with a specific customer. The question isn't "can this user see documents?" It's "can this user see this specific document based on their relationship to it?"
SpiceDB lets you model those relationships explicitly:
definition user {}
definition article {
relation viewer: user
permission view = viewer
}
Then you ask: "Does Alice have view permission on article:doc123?" SpiceDB answers based on actual relationships in its graph, not a coarse role lookup.
Enter langchain-spicedb
We've published langchain-spicedb, an authorization library for RAG pipelines that plugs SpiceDB into LangChain and LangGraph. It's vector-store agnostic — works with Pinecone, FAISS, Weaviate, Chroma, or anything that returns documents with metadata.
pip install langchain-spicedb[all]
The core pattern is post-retrieval filtering: retrieve the best semantic matches first, then check permissions before anything reaches the LLM. The library uses SpiceDB's CheckBulkPermissionsRequest API under the hood, so 100 documents cost one network call, not 100. API reference here
Three components, one decision
SpiceDBAuthFilter — for LangChain chains
If you're building with LCEL, SpiceDBAuthFilter slots between your retriever and your LLM. User identity is passed at runtime via configurable, so you build the chain once and reuse it across users:
from langchain_spicedb import SpiceDBAuthFilter
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
auth = SpiceDBAuthFilter(
spicedb_endpoint="localhost:50051",
spicedb_token="sometoken",
subject_type="user",
resource_type="article",
resource_id_key="article_id",
permission="view",
)
chain = (
RunnableParallel({
"context": retriever | auth, # authorization happens here
"question": RunnablePassthrough(),
})
| prompt
| llm
| StrOutputParser()
)
# Same chain, different users
answer = await chain.ainvoke(
"What is our litigation approach?",
config={"configurable": {"subject_id": "alice"}}
)
If you'd rather bundle retrieval and authorization into a single BaseRetriever — useful when dropping this into an existing pipeline that already expects a retriever — use SpiceDBRetriever instead:
from langchain_spicedb import SpiceDBRetriever
retriever = SpiceDBRetriever(
base_retriever=vector_store.as_retriever(),
subject_id="alice",
spicedb_endpoint="localhost:50051",
spicedb_token="sometoken",
resource_type="article",
resource_id_key="article_id",
)
docs = await retriever.ainvoke("query")
create_auth_node — for LangGraph workflows
For stateful, multi-step LangGraph workflows, authorization becomes a node in your graph. create_auth_node() and RAGAuthState handle the wiring:
from langgraph.graph import StateGraph, END
from langchain_spicedb import create_auth_node, RAGAuthState
graph = StateGraph(RAGAuthState)
graph.add_node("retrieve", retrieve_node)
graph.add_node("authorize", create_auth_node(
spicedb_endpoint="localhost:50051",
spicedb_token="sometoken",
resource_type="article",
resource_id_key="article_id",
))
graph.add_node("generate", generate_node)
graph.set_entry_point("retrieve")
graph.add_edge("retrieve", "authorize")
graph.add_edge("authorize", "generate")
graph.add_edge("generate", END)
app = graph.compile()
result = await app.ainvoke({
"question": "What is our litigation strategy?",
"subject_id": "alice",
})
The auth node reads retrieved_documents from state, runs the permission check, and writes back authorized_documents plus auth_results — a metrics dict with retrieved count, authorized count, denied IDs, and check duration.
If you need to handle multiple resource types or conditional auth paths, extend RAGAuthState with your own fields, or use AuthorizationNode directly to build reusable nodes across graphs.
SpiceDBPermissionTool — for agents
For LLM agents that need to check permissions before acting, the library ships with tools the agent can call directly:
from langchain_spicedb import SpiceDBPermissionTool
tool = SpiceDBPermissionTool(
spicedb_endpoint="localhost:50051",
spicedb_token="sometoken",
subject_type="user",
resource_type="article",
)
result = tool.invoke({
"subject_id": "alice",
"resource_id": "doc123",
"permission": "view"
})
# Returns: "true" or "false"
SpiceDBBulkPermissionTool handles multiple resources in a single call.
A quick decision guide
- Simple LCEL chain? →
SpiceDBAuthFilter - Existing retriever-based pipeline? →
SpiceDBRetriever - Stateful, multi-step LangGraph workflow? →
create_auth_node - Agent that checks permissions on the fly? →
SpiceDBPermissionTool
The bigger picture
RBAC was built for login screens and admin panels — a finite set of actions on a finite set of resource types. AI applications don't work that way. Documents are dynamic, relationships are specific, and the LLM will answer from whatever it gets. You can't patch authorization on afterwards.
The industry spent a decade learning to take authorization seriously for web applications. RAG is forcing us to learn it again — faster, and with higher stakes.
langchain-spicedb is on PyPI and GitHub. Try it, break it, and open an issue when you do.
Next steps
The PR to make it an official LangChain integration is here.
Here's a production-style example that uses Weaviate as the vector database and the LangGraph integration for fine-grained SpiceDB authorization.