
On February 16th 2022, while rolling out new metrics for the billing section of permission systems on Authzed, we noticed consistently higher API latency with occasionally large spikes into the hundreds of milliseconds. At no point in time was there a full service outage, but because exceeding our target SLOs can directly affect our users' own deadlines, this type of outage is taken equally seriously. Typical service interruptions can be mitigated by rolling back software or introducing new code to fix the identified problem, but in this case the root cause was determined to have been always present in our deployment and was made observable once fully exercised with the introduction of our new functionality.
We’re sharing these technical details to give our users an understanding of the root cause of the problem, how we addressed it, and what we are doing to prevent similar issues from happening in the future. We would like to reiterate there was no user data loss or access by unauthorized parties of any information during the incident.
Timeline
- 2022/02/16 03 ET - Initial production rollout, new metrics feature flagged on
- 2022/02/16 04 ET - New metrics are feature flagged off
- 2022/02/16 04 ET - SpiceDB is rolled back
- 2022/02/16 04 ET - Full deployment rollback
- 2022/02/18 11 ET - Root Cause is hypothesized
- 2022/02/19 04 ET - Fix is proven correct on staging
- 2022/02/19 05 ET - Fix is deployed to production
Deep Dive
Authzed provides a serverless platform for SpiceDB. Like most serverless products, billing is calculated via usage metrics. Because these metrics are so critical to understanding how users are charged, the development team has been working to maximize the transparency and understanding users have with these metrics. On the 16th, we introduced various changes on Authzed related to billing and its metrics. Only after a production deployment and many minutes of actual user traffic was there a large enough increase in API latency to cause the on-call SRE to be paged. Our first lead was that these new dashboards were the root cause of our incident. We started by disabling functionality with feature flags before attempting a partial, followed by a full rollback of the software. The full rollback ultimately returned the service to its previous stability, but we realized that this was not going to be a normal incident when our attempts to perform partial rollbacks had had no effect.
It was ultimately determined that the traffic generated from a sufficient number of simultaneous users loading and idling on these billing dashboards was the source of our latency issues. Because the metrics powering our billing pages are sourced by our users' querying Prometheus, we immediately suspected prom-authzed-proxy, our open source proxy that secures Prometheus by performing a SpiceDB permission check. This proxy has reliably operated in production, so we had not felt the need to update it to leverage the latest version of the SpiceDB API. We spent time analyzing the proxy and merging a PR that updated its API usage, but to no avail.
Our next lead was Prometheus itself, which we noticed was spiking its CPU usage while handling some of the complex billing queries. Despite having resource quotas defined in Kubernetes, there was still plenty of time for CPU spikes to affect colocated pods before the quota was applied. This window for how quickly pods are throttled when they exceed these limits is configurable, but as a flag on the control plane that affects the entire cluster. Our determination was to move our latency sensitive workloads over to a dedicated nodepool where non-critical workloads such as Prometheus could not be scheduled. While this did not directly resolve the problem, it ultimately became a part of the resolution.
With the proxy and Prometheus itself out of the way, there was only one moving part left to analyze: SpiceDB. Our hypothesis was that the traffic patterns were able to cause undesirable internal behavior in SpiceDB, such as cache ejection/invalidation. We discovered that caching could be improved by exposing more configuration and defaulting to better values, but this did not explain what we were observing. Our next idea was that it could be related to how SpiceDB picks revisions for requests that do not specify the consistency they require. It was possible that traffic was getting backed up due to a thundering herd when the latest cached revision became invalid. It was the exploration of this idea that ultimately led to the discovery of the root cause.
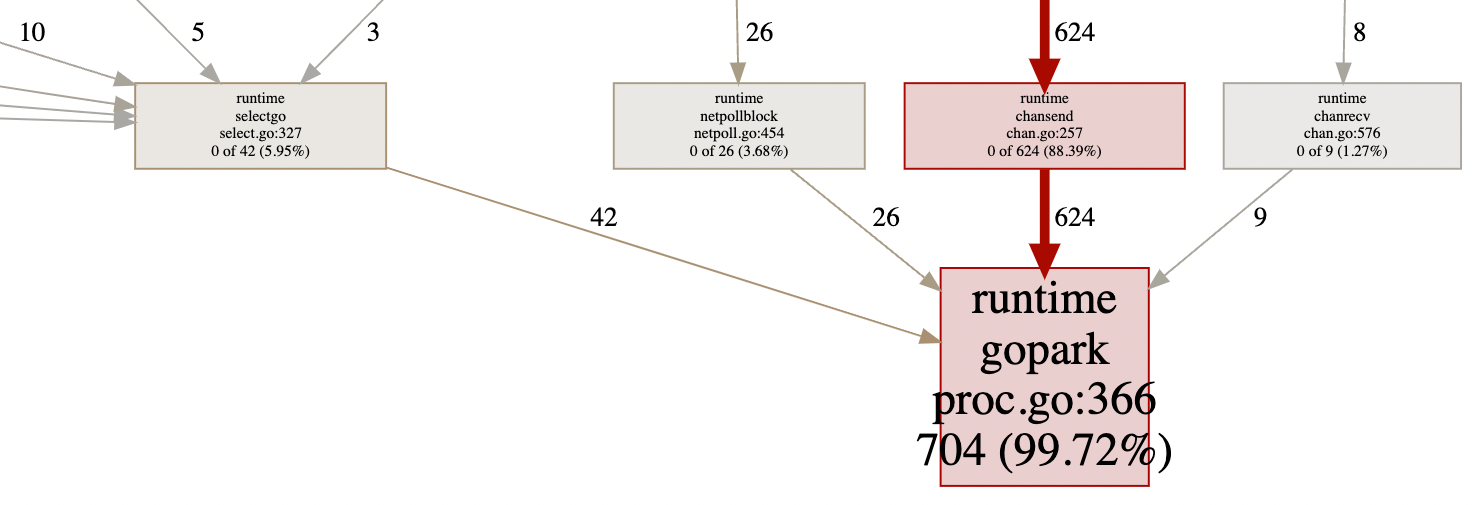
In order to determine if traffic was being blocked during latency spikes, we wrote a shell script to perform a large number of queries through prom-authzed-proxy and took goroutine profiles of SpiceDB while it ran. These profiles revealed a surprisingly large number of goroutines parked. This meant that Go runtime was struggling to maintain the throughput necessary to process all of the incoming requests. There are two ways to address such a problem: increase the number of cores available to SpiceDB or optimize SpiceDB to be conscious of its impact on the Go scheduler.
After updating the latency-sensitive nodepool in our staging cluster and observing the performance issues completely disappear, the on-call engineer moved forward with promoting production to the latest version of our software with SpiceDB running on VMs with additional cores.
Post-outage System Stability
Following our resolution for the outage, overall API latency has not only returned to normal, but improved 27% (from an average of 22ms to 16ms). Additionally, we're eager to see how some of our ideas to solve SpiceDB red herrings might also positively impact API latency for not only Authzed customers, but also open source SpiceDB users.
Closing Thoughts & Next Steps
We'd like to thank our users for their patience, understanding, and support during this time. We'd also like to extend a huge thanks to all of the Authzed employees that worked both in and out of working hours to resolve this incident. While conducting a post-mortem is a blameless process, it does not excuse those involved from taking responsibility. We've identified various next steps to improve our processes and avoid future issues, some of which have already been implemented:
- Improving external communication by
- automating the creation of status page incidents based on metrics
- documenting recommended hardware resources for SpiceDB
- Improving internal communication by
- adding webhooks to various parts of our process to self-document our workflows
- creating a dedicated forum for on-call discussion
- Improving the software promotion process by
- analyzing stability for longer periods of time before promotion
- adding continuous profiling
- refining SOPs with regards to how and when to perform rollbacks
- Improving the software by
- adding control mechanisms for the growth of the number of goroutines
- removing any background queries to Prometheus when not viewing billing
- developing additional performance improvements around API operations
- integrating regular scale testing into the development workflow
We have learned tremendously from this experience and would like to again thank all those involved and affected for their contribution in making Authzed and SpiceDB a more performant and resilient platform going forward.
Did you find this post interesting? We're hiring SREs to join us on our journey.
