
Overview
The dual-write problem presents itself in all distributed systems. A system that uses SpiceDB for authorization and also has an application database (read: most of them) is a distributed system. Working around the dual-write problem typically requires a non-trivial amount of work.
What is the Dual-Write Problem?
If you've heard this one before, feel free to skip down where we talk about solutions and approaches to the dual-write problem. If it's your first time, welcome!
Let's consider a typical monolithic web application. Perhaps it's for managing and sharing files and folders, which makes it a natural candidate for a relation-based access control system like SpiceDB. The application has an upload endpoint that looks something like the following:
def upload(req):
validate_request(req)
with new_transaction() as db:
db.write_file(req.file)
return Response(status=200)
All of the access control logic is neatly contained within the application database, so no other work needed to happen up to this point. However, we want to start using SpiceDB in anticipation of the application growing more complex and services splitting off of our main monolith.
We start with a simple schema:
definition user {}
definition folder {
relation viewer: user
permission view = viewer
}
definition file {
relation viewer: user
relation folder: folder
permission view = viewer + folder->viewer
}
Note that if a user is a viewer of the folder, they are able to view any file within the folder. That means that we'll need to keep SpiceDB updated with the relationships between files and folders, which is held in the folder relation on the file.
That doesn't sound so bad. Let's go and implement it:
def upload(req):
validate_request(req)
with new_transaction() as db:
file_id = db.write_file(req.file)
write_folder_relationship(
file_id=file_id
folder_id=req.folder_id
)
return Response(status=200)
We've got a problem, though. What happens if the server crashes? We're going to use a server crash as an example problem because it's relatively conceptually simple and is also something that's hard to recover from. Let's mark up the function and then consider what happens if the server crashes at each point:
def upload(req):
validate_request(req)
# point 1
with new_transaction() as db:
file_id = db.write_file(req.file)
# point 2
write_folder_relationship(
file_id=file_id
folder_id=req.folder_id
)
# point 3
# point 4 (outside of the transaction)
return Response(status=200)
Note that the points refer to the boundaries between lines of code, rather than pointing at the line of code above or below them.
Here's an alternative view of things in a sequence diagram:
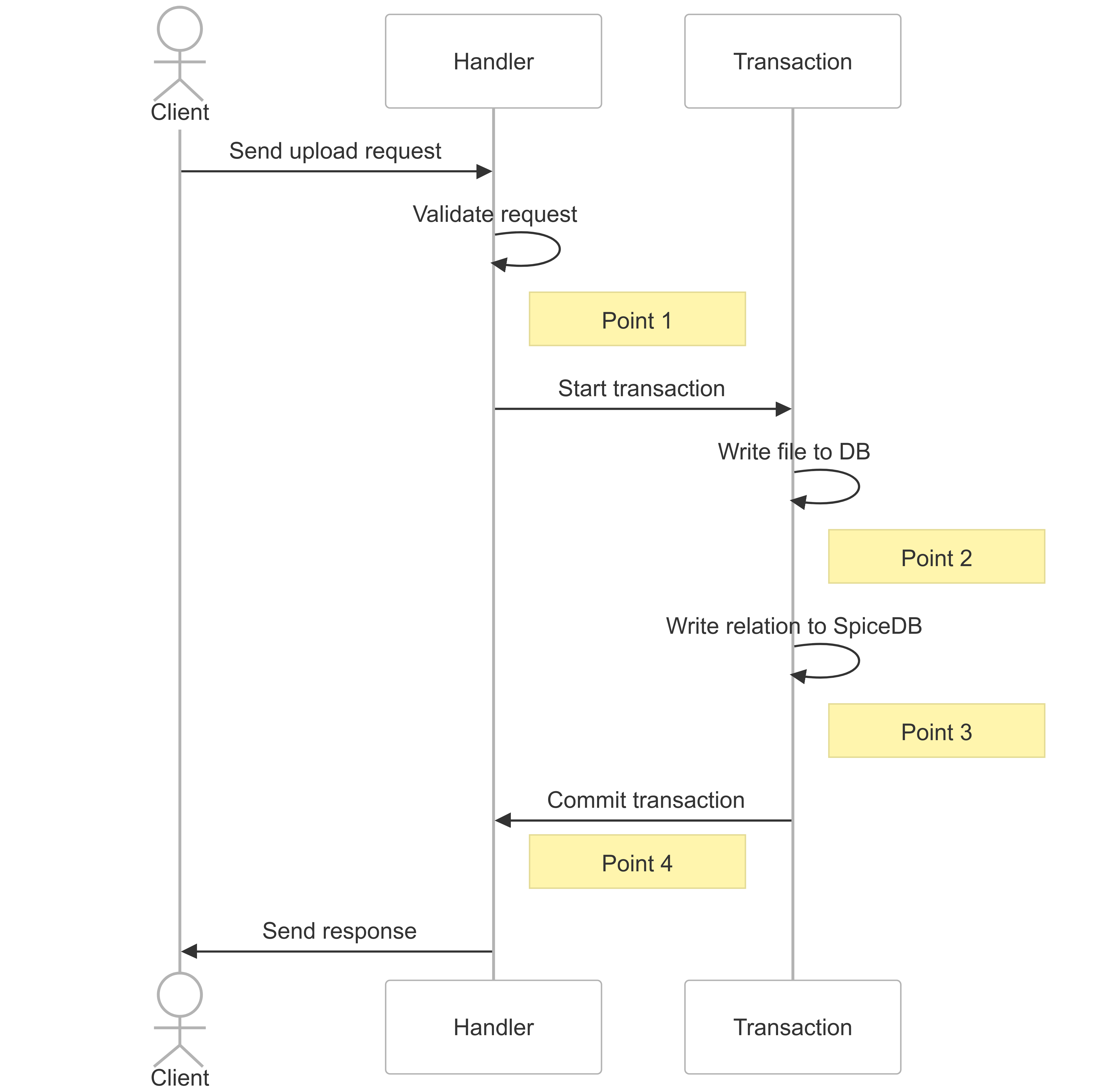
If the server crashes at points #1 or #4, we're fine - the request will fail, but we're still in a consistent state. The application server and SpiceDB agree about what the system should look like. If the server crashes at point #2, we're still okay - we've opened a database transaction but we haven't committed it, so the database will roll back the transaction and everything will be fine. If we crash at point #3, however, we're in a state where we've written to SpiceDB but we haven't committed the transaction to our database, and now SpiceDB and our database disagree about the state of the world.
There isn't a neat way around this problem within the context of the process, either. This blog post goes further into potential approaches and their issues if you're curious. Things like adding a transactional semantic to SpiceDB or reordering the operations move the problem around but don't solve it, because there's still going to be some boundary in the code where the process could crash and leave you in an inconsistent state.
Note as well that there's nothing particularly unique about the dual-write problem in systems using SpiceDB and an application database, either. If we were writing to two different application databases, or to an application database and to a cache, or to two different RPC-invoked services, we still have the same issue.
So what can we do?
We can solve the dual-write problem in SpiceDB using a few different approaches, each with varying levels of complexity, prerequisites, and tradeoffs to be made
Do Nothing
Doing nothing is an option that may be viable in the right context. The sort of data inconsistency where SpiceDB and your application database disagree can be hard to diagnose. However, if there are mechanisms by which a user could recognize that something is wrong and remediate it in a timely manner, or if the authorized content in question isn't particularly sensitive, you may be able to run a naive implementation and avoid the complexity associated with other approaches. The more stable your platform is, the more likely this is to cause fewer issues.
Out-of-band consistency checking
Out-of-band consistency checking would be one step beyond "doing nothing." If you have a source of truth that SpiceDB's state is meant to reflect in a given context, you can check that the two systems agree on a periodic basis. If there's disagreement, the issues can be automatically remediated or flagged for manual intervention.
This is a conceptually simple approach, but it's limited by both the size of your data and the velocity of changes to your data. The more data you have, the more expensive and time-consuming the reconciliation process becomes. If the data change rapidly, you could have false positives or false negatives when a change has been applied to one system but not the other. This could theoretically be handled through locking or otherwise pinning SpiceDB and your application's database so that their data reflect the same version of the world while you're checking their associated states, but that will greatly reduce your ability to make writes in your system. The sync process itself can become a source of drift or inconsistency.
Make SpiceDB the source of truth
For certain kinds of relationships and data, it may be sufficient to make SpiceDB the source of truth for that particular information. This works best for data that matches SpiceDB's storage and access model: binary presence or absence of a relationship between two objects, and no requirement to sort those relationships or filter by anything other than which subject or object they're associated with.
If your data meet those conditions, you can remove the application database from the question and make a single write to SpiceDB and avoid the dual-write problem entirely.
For example, if we wanted to add a notion of a file "owner" to our example application, we probably wouldn't need an owner column with a foreign key to a user ID in our application database.
Instead, we could represent the relationship entirely with an owner relation in SpiceDB, such that an API handler for adding or updating an owner of a file or folder would only talk to SpiceDB and not to the application database.
Because only one system is being written to in the handler, we avoid the dual-write problem.
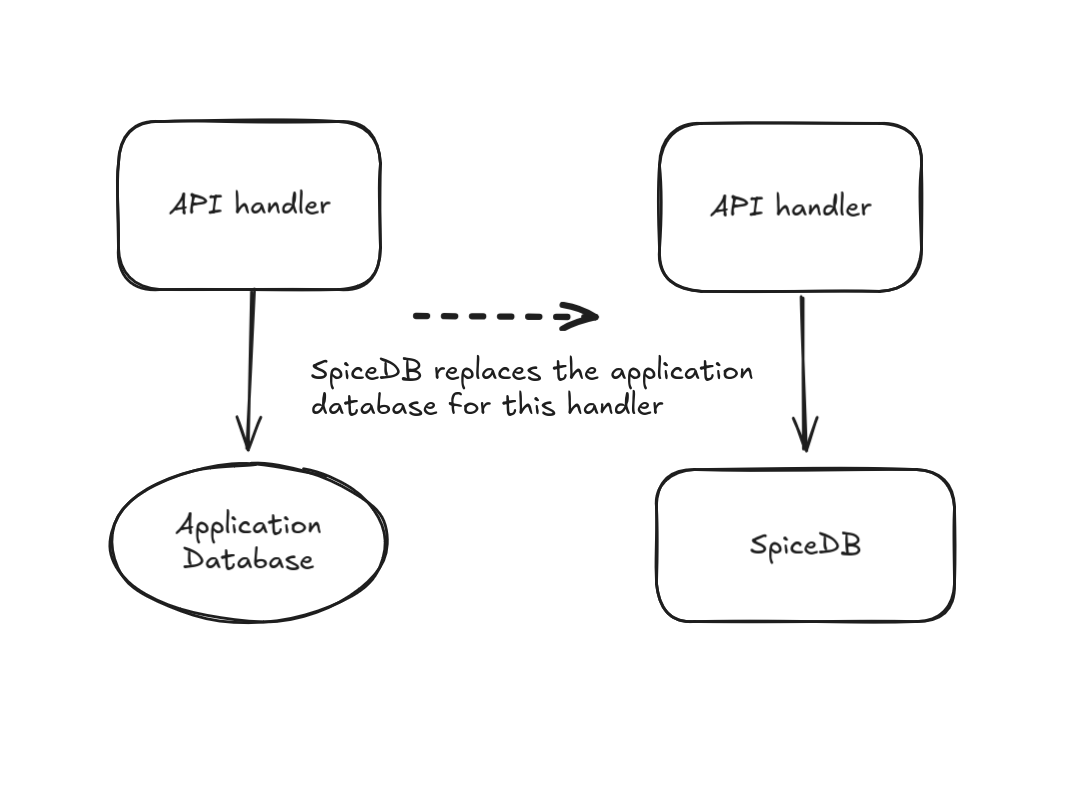
The limitation here is that if you wanted to build a user interface where a user can see a table of all of the files they own, you wouldn't be able to filter, sort, or paginate that table as easily, because SpiceDB isn't a general-purpose database and doesn't support that functionality in the same way.
Event Sourcing/Command-Query Responsibility Segregation (CQRS)
Event sourcing and CQRS are related ideas that involve treating your system as eventually consistent. Rather than an API call being a procedure that runs to completion, an API call becomes an event that kicks off a chain of actions. That event goes into an event stream, where consumers (to use Kafka's language) can pick them up and process them, which may involve producing new events. Multiple consumers can listen to the same topic. The events flow through the system until they've all been processed, and the surrounding runtime ensures that nothing is dropped.
There's a cute high-level illustration of how an event sourcing system works here: https://www.gentlydownthe.stream/
In our example application, it might look like the following:
- A client makes a request to create a file in a folder
- The API handler receives the request and puts a message into the event stream that includes the information about the file
- One consumer picks up the creation message and writes a relation to SpiceDB between the file and its folder
- Another consumer picks up the creation message and writes the information about the file to the application database
The upside is that you're never particularly worried about the dual-write problem, because any individual failure of a subscriber can be recovered and re-run. Everything just percolates through until the system arrives at a new consistent state.
The downside is that you can't treat API calls as RPCs. The API call doesn't represent a change to the state of your system, but rather a command or request that will eventually result in your desired changes happening. You can work around this by having the client or UI listen to an event stream from the backend, such that all you're doing is passing messages back and forth, but this often requires significant rearchitecture, and not every runtime is amenable to this architecture.
Here are some examples of event queues that you might see in an event sourcing system:
Durable Execution Environments
A durable execution environment is a set of software tools that let you pretend that you're writing relatively simple transactional logic within your application while abstracting over the concerns involved in writing to multiple services. They promise to take care of errors, rollbacks, and coordination, provided you've written the according logic into the framework.
An upside is that you don't have to rearchitect your system if you aren't already using the paradigms necessary for event sourcing. The code that you write with these systems tends to be familiar, procedural, and imperative, which lowers the barrier to entry for a dev trying to solve a dual-write problem.
A downside is that it can be difficult to know when your write has landed, because you're effectively dispatching it off to a job runner. The business logic is moved off of the immediate request path. This means that the result of the business logic is also off of the request path, which raises a question of what you would return to an API client.
Some durable execution environments are explicitly for running jobs and don't give you introspection into the results; others can be inserted into your code in such a way that you can wait for the result and pretend that everything happened synchronously. Note that this means that the associated runtime that handles those jobs becomes a part of the request path, which can carry operational overhead.
Temporal, Restate, Windmill, Trigger.dev, and Inngest are a few examples of durable execution environments. You'll have to evaluate which one best fits your architecture and infrastructure.
Transactional Outbox Patterns
A transactional outbox pattern is related to both Event Sourcing and Durable Execution, in that it works around the dual-write problem through eventual consistency. The idea is that within your application database, when there's a change that needs to be written to SpiceDB, you write to an outbox table, which is an append-only log of modifications that should happen to SpiceDB. That write can happen within the same database transaction, which means you don't have the dual write problem. You then read that log (or subscribe to a changestream) with a separate process which marks the entries as it reads them and then submits them to SpiceDB through some other mechanism.
As long as this process is effectively single-threaded and retries operations until they succeed (which is helped by SpiceDB allowing for idempotent writes with its TOUCH operation), you have worked around the dual-write problem.
One of the most commonly-used tools in a system based on the transactional outbox pattern is Debezium. It watches changes in an outbox table and submits them as events to Kafka, which can then be consumed downstream to write to another system.
Some other resources are available here:
- https://www.decodable.co/blog/revisiting-the-outbox-pattern
- https://docs.aws.amazon.com/prescriptive-guidance/latest/cloud-design-patterns/transactional-outbox.html
So which one should I choose?
Unfortunately, when making writes to multiple systems, there are no easy answers. SpiceDB isn't unique in this regard, and most systems of sufficient complexity will eventually run into some variant of this problem. Which solution you choose will depend on the shape of your existing system, the requirements of your domain, and the appetite of your organization to make the associated changes. We still think it's worth it - when you centralize the data required for authorization decisions, you get big wins in consistency, performance, and safety. It just takes a little work.