
A hypothetical scenario
Say you're hosting an exclusive wedding party with a guest list. How do you decide at the door if someone is getting in or not?
Easy! How about if only the people with the invite letter can enter? Well, this is an exclusive wedding party and people can sell these invitations, create fake ones, or even lose the original invitation letter. What then?
Your next thought is to hire a bouncer. There's a guest list that the bouncer has access to, and they make the decision on who can enter. For a nightclub, this rule-based approach works fine: adhere to the dress code, pay the $20 entry and you're in. That's stateless. But for a wedding party this is complicated. What if things change after the list prints? Turns out the host was kicked out of their D&D group so the group is uninvited to the wedding. Changes between list creation and decision time create gaps that the bouncer might not know of.
For a wedding, you need contextual information about relationships, feuds, and edge cases to make a decision. Let's call this ambient context. You generate a guest list, print invitations, and give the bouncer the host's phone number. All that prep distills context into a format the bouncer can execute. This is exactly what we do with policy engines using JWTs, certificates, and access control lists.
Clearly a bouncer is not the solution here so the ideal scenario is: put the host at the door. The host decides who comes to their wedding party. But then the host misses their own party. Here's where having a clone of the host would help.
A system that closely resembles cloning the host and putting them at the door is Relationship-Based Access Control (aka ReBAC). The clone knows who everybody is, and can inherently grant access based on their relationships. The host enjoys the party while the clone makes decisions based on all the ambient context. The underlying methodology could be extended to work for any wedding, not just this specific guest list.
A fundamental mismatch
At AWS reInvent in December 2025, Amazon announced they'd built their Cedar policy engine into Bedrock's agent core. Cedar was also donated to the CNCF. The momentum behind policy engines for AI authorization seems real.
But there's a fundamental mismatch here. The same reasons that relationship-based access control matters for humans will resurface, and matter even more, for AI agents.
The policy engine promise
At its core a policy engine is a computer program that evaluates data and returns yes or no. The flexibility is the selling point. Policy engines don't care who should access what or why. They just run your code against whatever data you feed them.
Performance numbers of policy engines get thrown around a fair amount: 50 microseconds here, 600 nanoseconds there. Those numbers are real, but they hide the catch that you still have to collect all the data and deliver it to the policy engine before that fast evaluation happens.
A Cedar example
Cedar's own documentation shows the problem. Their photo sharing app example uses 57 lines to define a user named Alice, her group memberships, a photo, and an account owner. The schema adds another 131 lines (!) for entity types and actions.
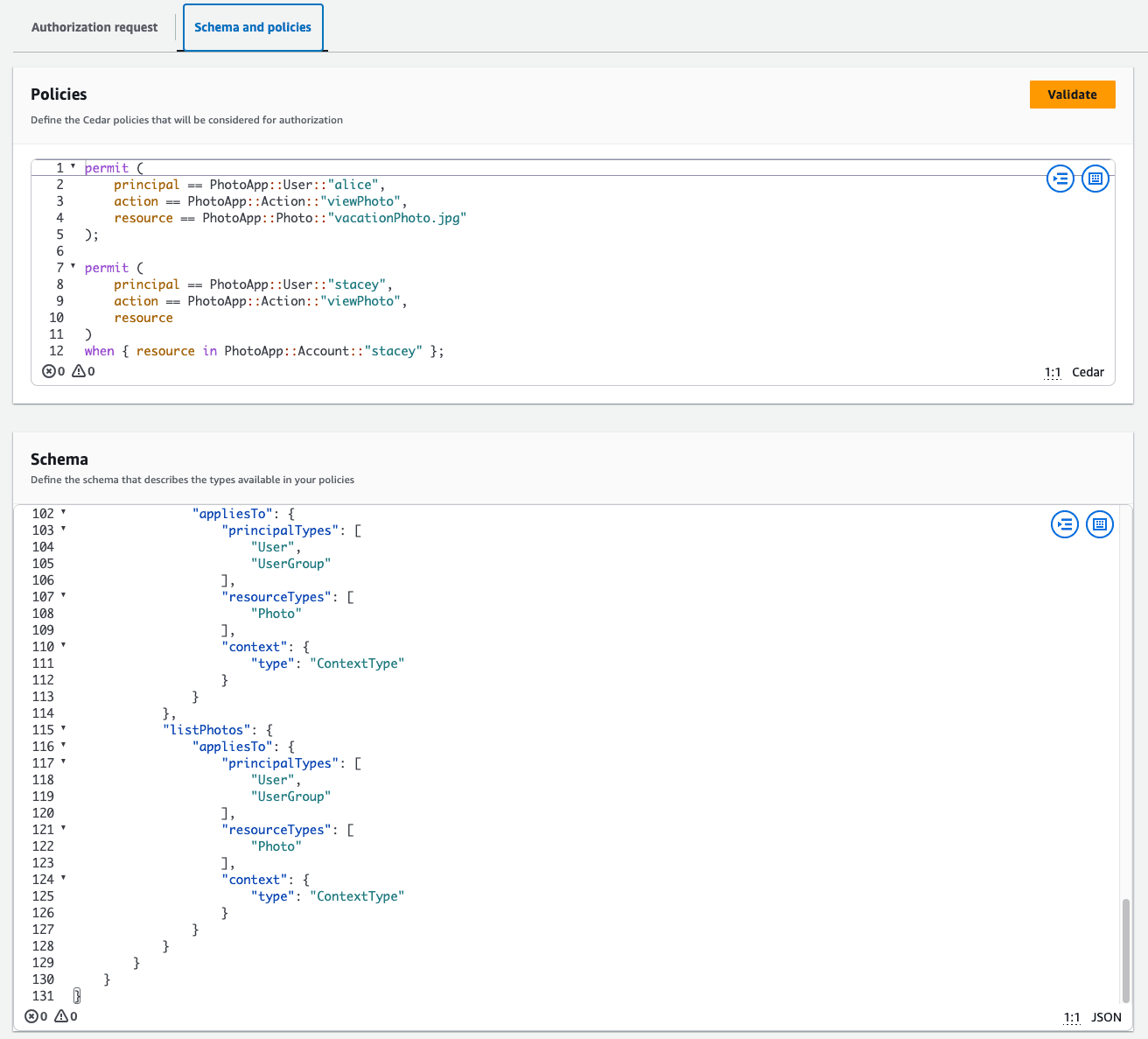
After assembling this data, the policy directly grants Alice access to the vacation photo. All that relationship data about groups and membership gets ignored. Every time Alice needs access to another photo, you'd write another similar block!
For a system claiming to handle authorization at scale, this approach doesn't hold up.
What ReBAC offers
Relationship-based access control works differently. Most access decisions stem from relationships between the different entities in a system such as users, photos, folders etc. Alice belongs to some groups. Photos are shared with those groups. Alice can also see her own photos.
The SpiceDB schema language combines data and policy into a single permission system. Anyone can ask the same question and get the same answer. The system optimizes around the data it already has and accounts for all the ambient context that is required to make the correct decision.
The same photo sharing example from above needs just 20 lines of SpiceDB schema. The objects defined in the system are user, usergroup, album , account and photo. And the relationships between these objects are also expressed within the schema. For example: A user is a member of a usergroup
When your app grows, the schema grows with it.
/**
* user represents a user that can be granted role(s)
*/
definition user {}
definition usergroup {
relation member: user
}
definition album {}
definition account {}
definition photo {
relation member: account | album
permission view = member
permission create = nil
permission list = nil
}
Adding a new permission like "share" means writing the logic for who can share, and SpiceDB handles the rest.
How AI agents change things
Right now, we treat AI agents like computers. We pre-decide their access and write policies for what they can reach. But agents will increasingly work like humans. We'll share documents with them, add them to teams, and grant access dynamically.
The shift from RAG to Model Context Protocol makes this concrete. RAG precomputed everything and stuffed it into context. MCP lets agents reach out to data sources, assemble what they need, then fetch more based on what they found.
Adding agent support to a SpiceDB schema takes just one line as it is just a new object in the schema.
definition agent {}
Then relationships work naturally:
relation shared_with: user | agent
The permission system doesn't distinguish between users and agents at the relationship level. This is because agents aren't users. They don't have birthdays or t-shirt sizes. They often have long machine-generated names. You might want a hard rule that agents can never delete photos, which you'd enforce by making delete permissions only resolve to user entity types.
Service accounts hit this pattern years ago. The same problem will hit harder with agents, because generating a new agent takes seconds. Organizations will eventually have many more agents than human users.
Policy engines aren't wrong everywhere
Policy engines make sense when all the decision data exists in the request. An example of where a policy engine is a perfect fit is a HTTP Filter - An HTTP request from a known IP to a specific URL doesn't need outside context. The decision is fast because you already have all the data needed to make a decision in the request.
The problem surfaces when you need ambient context about how objects relate to each other. Trying to cram relationship graphs into stateless policies creates the same friction as the wedding guest list as you're constantly playing catch-up with changes.
Why this matters for AI
It's no surprise that Broken Access Control topped the OWASP Top 10 list in 2025 (and 2021) and this problem will be exacerbated as AI systems evolve.

Access control will soon need to track:
- Which documents an agent accessed
- What an agent requested versus received
- When permissions changed mid-task
- How agent capabilities map to user permissions
Agents will request access dynamically. Systems will make just-in-time decisions. Ambient context that constantly shifts as agents work and permissions update, doesn't fit the policy engine model.
If you could predict what agents would do ahead of time, they'd just be workflows. The agency means you can't write a fixed policy that accounts for all possible actions. You need a system that evaluates permissions against current relationship state, not pre-compiled policies.
Here's a video where Jake Moshenko, CEO of AuthZed talks about why Policy Engines fall short when it comes to AI Agent Authorization.
The path forward
Authorization has accumulated many approaches over the years:
- Access control lists: explicit lists of who can read or edit
- Role-based access control: assign roles that grant permissions
- Attribute-based access control: decide based on user and resource attributes
- Policy-based access control: run code to make decisions
- Relationship-based access control: permissions derive from relationship chains
None of these will disappear. But for AI authorization, where relationships shift constantly and context accumulates during execution, forcing everything through policy engines creates more problems than it solves.
The market converging on Zanzibar-style systems isn't an accident. Google built Zanzibar to handle dynamic, relationship-driven authorization at scale, and SpiceDB brings that architecture to teams facing similar problems.
The industry learned this lesson for human users over the past decade. We're learning it again for AI agents.