
At AuthZed we’re building SpiceDB, a distributed authorization system inspired by Google's Zanzibar. Zanzibar is slowly becoming a household name, and you may already be familiar with how a ReBAC model can simplify your authorization needs.
The crux of the Zanzibar paper is not that modeling permissions as a graph is cool or fun, even though it is—but rather that doing so, carefully, can unlock scale and performance that authorization services of yore failed to deliver.
Performance and scale are critical for an authorization service like SpiceDB. In this post, we’ll discuss some of the challenges we faced scaling SpiceDB on top of CockroachDB and how we solved them.
If you’re just interested in the what and not the why or the how, feel free to jump directly to the advanced connection pooler we implemented to get the best performance from CockroachDB at scale.
Scaling SpiceDB to 1 Million QPS
We recently scale-tested SpiceDB on CockroachDB to 1 million authorization events per second with 1% writes and 100 billion stored relationships. During that work, we uncovered (and fixed!) several scaling limits in SpiceDB.
We’ll cover the SpiceDB side of things in more depth in a future blog post—here we’ll focus on some of the issues we found running a CockroachDB cluster at those scales:
- Uneven load across CockroachDB nodes would artificially cap the capacity of the cluster. Answering one
CheckPermissioncall to SpiceDB uses multiple connections to CockroachDB from multiple SpiceDB nodes. If one CockroachDB node is serving 10% more connections than the others, this manifests as lower max throughput in SpiceDB—there's a high chance that at least one query will be made against the overloaded CockroachDB node. - Connection latency to CockroachDB increases SpiceDB's latency. Even though connections are infrequent compared to queries, they affect SpiceDB's tail latencies at scale. At high QPS, there are few idle connections in the pool, which will force a small fraction of requests to block while waiting for a new connection.
Both of these problems require that SpiceDB develop a deeper understanding of the CockroachDB cluster that it’s talking to. Evening out unbalanced connections requires SpiceDB to be able to identify the Cockroach node for a given connection—information it doesn’t normally have. And changing connection counts and pool settings are constrained by the drain timeouts that we’ve written about before—there aren’t many knobs we can turn without finding a way to increase connection lifetimes beyond the drain timeout.
Addressing Uneven Connection Load in CockroachDB
When SpiceDB starts up, it creates a pool of connections against CockroachDB using pgx. Connection pooling allows us to pay the cost of the relatively slow connection handshake infrequently, with queries only waiting to acquire an idle connection from the pool rather than waiting to open a brand-new connection against the database.
In the case of a clustered database like CockroachDB, the connection is actually to just one of the many gateway nodes. In a typical CockroachDB cluster, any node may be a gateway node. The gateway node for a query handles coordination and execution of the query and maintains the connection state for the life of the connection.
Identifying a CockroachDB Gateway Node
The first order of business in solving this uneven load is to identify the gateway node for a given connection in the pool, but this is easier said than done.
DNS can’t be used to identify nodes because they run behind a load balancer. Here’s the dig response for a brand new 1-node Cockroach Cloud Dedicated Cluster in AWS:
;; ANSWER SECTION:
lonely-mouse-k8r.aws-us-east-1.cockroachlabs.cloud. 60 IN CNAME a0db5b4d680eb43eebc8208bba96426f-b066d004158f38f0.elb.us-east-1.amazonaws.com.
a0db5b4d680eb43eebc8208bba96426f-b066d004158f38f0.elb.us-east-1.amazonaws.com. 60 IN A 3.81.194.175
a0db5b4d680eb43eebc8208bba96426f-b066d004158f38f0.elb.us-east-1.amazonaws.com. 60 IN A 44.216.20.128
a0db5b4d680eb43eebc8208bba96426f-b066d004158f38f0.elb.us-east-1.amazonaws.com. 60 IN A 3.231.250.16
a0db5b4d680eb43eebc8208bba96426f-b066d004158f38f0.elb.us-east-1.amazonaws.com. 60 IN A 52.201.170.79
a0db5b4d680eb43eebc8208bba96426f-b066d004158f38f0.elb.us-east-1.amazonaws.com. 60 IN A 44.216.9.122
a0db5b4d680eb43eebc8208bba96426f-b066d004158f38f0.elb.us-east-1.amazonaws.com. 60 IN A 100.25.32.220
The response only shows addresses for ELBs, and not for CockroachDB nodes themselves.
Once we already have a connection, it’s possible to identify the node handling the connection with a SQL query: SHOW node_id; . A pgx hook would allow us to issue this query after every new connection is established.
However, using a SQL query for each check adds a roundtrip and adds latency when creating every new connection. This wouldn’t be the end of the world since connection time is amortized via the connection pool, but it would be better if we could avoid any unnecessary roundtrips.
A Brief Sojourn in the Postgres Wire Protocol
It turns out that we can remove the need for the round trip, but it requires digging into the Postgres wire protocol and the way that CockroachDB implements it.
The Postgres wire protocol sends a BackendKey when it establishes a new connection with a client. The BackendKey includes two fields, ProcessID and SecretKey. In a real Postgres server, the ProcessID is the PID of the process that is handling the current session, and the SecretKey is unique per session and is for canceling a running query (out of band, on a new connection). In the wire protocol, this BackendKey is a single 64-bit field.
CockroachDB doesn't assign a process per connection like Postgres does. Instead, a SqlInstanceID and random data get encoded into the BackendKey in one of two ways:
- A 12-bit node ID and 52 bits of random data. This is used when talking to single-tenant CockroachDB (i.e., Cockroach Dedicated) nodes.
- A 32-bit instance ID and 32 bits of random data. This is used when talking to multi-tenant CockroachDB (i.e. Cockroach Serverless) nodes - it is stable for a single SQL instance but may not correspond to the physical node ID.
The first bit in the CockroachDB encoding of BackendKey is a sentinel bit that indicates which of these encodings is used.
In both cases, random data fills the SecretKey portion of the BackendKey, and for compatibility with Postgres, this value can also be used to cancel running queries. CockroachDB also has a separate first-class CANCEL QUERY command, so there's likely not much reason to use the SecretKey for its original purpose.
This diagram shows how CockroachDB and Postgres encode and decode the bits of the BackendKey field:
0 1 2 3 4 5 6
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Postgres ProcessID | Postgres SecretKey |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|0| Short ID (Node ID) | Random Data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|1| Long ID | Random Data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
For tracking connections to CockroachDB nodes, this means that the ProcessID can be used to track which nodes have connections, and it's a value we can recover from the initial handshake without any additional roundtrips to run SHOW node_id;.
Tracking CockroachDB Node Connections
In order to track how many connections SpiceDB has to each node, we need to know any time they're added and removed from the connection pool.
pgxpool provides an AfterConnect hook which we can use to track new connections as they are made, but it lacks a BeforeClose hook so that we can know when connections are removed from the pool. Or rather, pgxpool used to lack a BeforeClose hook until we contributed it.
With both hooks in place, and the ability to identify the gateway node for a connection, we can easily track how many connections we have to each CockroachDB node.
Client-Side Balancing Through a Load Balancer
Now that we’re able to track connections properly, we need to tackle evenly balancing connections across all of the CockroachDB nodes.
But how do we make sure we have an even balance among all of the nodes? SpiceDB is unable to make any decisions about which node it connects to.
The solution is simple if somewhat brutish: if we see that a node has disproportionately more connections than it should, we can kill some of the excess connections. More precisely, we mark them to be recycled when their current queries are done.
When new connections are established, they will have the opportunity to connect in a more balanced way. If we prune connections to over-connected nodes iteratively, eventually, we will have a balanced set of connections.
We prune proportionally more connections the further away from the target the number of connections is for a node, and rate limit the addition of new connections. This prevents a thundering herd when nodes are added or restarted. The pruning algorithm is similar to the Additive Increase / Multiplicative Decrease congestion control that TCP performs, but instead of congestion, we're measuring the distance from a desired connection count.
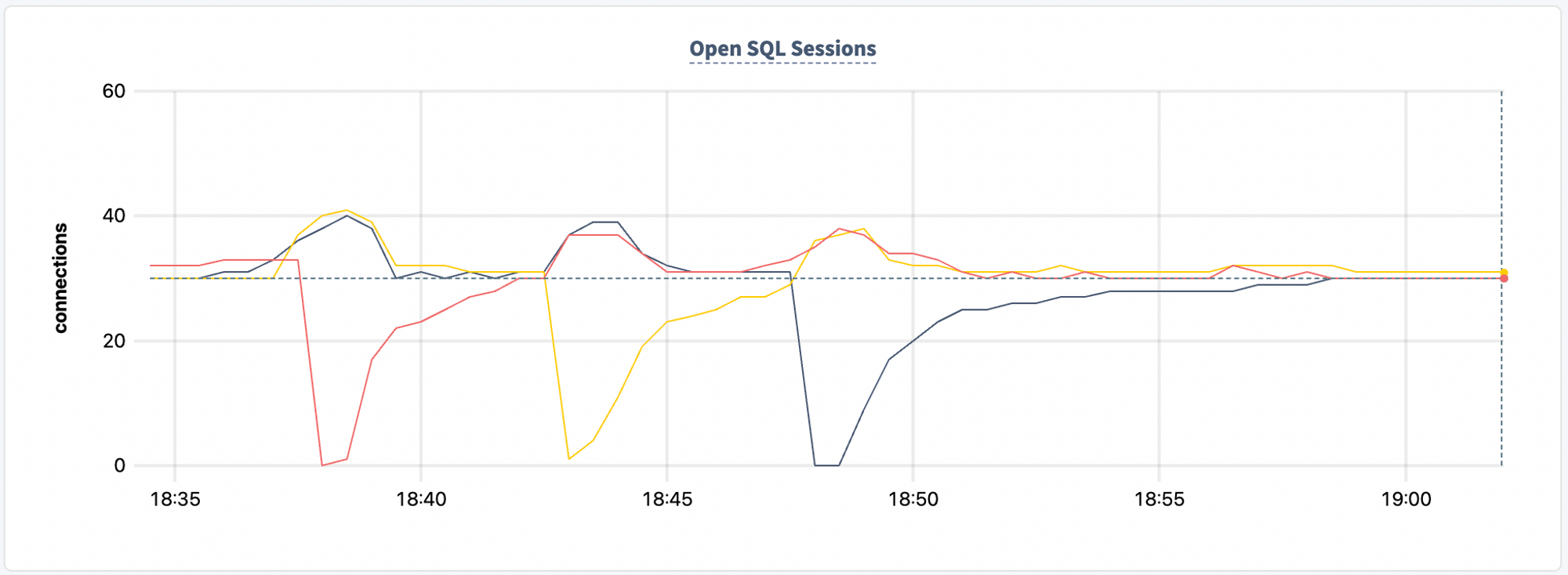
Actually getting to stable connection counts like this graph shows, requires a little extra work to deal with cases where the number of connections does not divide evenly between the nodes. But that is left as an exercise to the reader (or you can read the code).
Amortizing Connection Latency
Now that we've figured out how to get a set of SpiceDB nodes to balance their connections evenly across all CockroachDB nodes, we can shift focus to the connection-latency-induced tail latencies.
When we increase the number of SpiceDB nodes talking to a CockroachDB cluster, we need to decide how many connections each SpiceDB instance should have in its pool.
- If we don't decrease the number of connections that each SpiceDB node is allowed, then the overall number of connections to CockroachDB increases. This means more connections are expiring and reconnecting in any given time window, which increases the time it takes to establish any single connection. This can increase tail latency in SpiceDB.
- If we decrease the number of connections each SpiceDB node is allowed, we may stabilize the latency to establish a single connection, but more requests may need to wait to acquire a connection from the pool. This can also increase tail latency in SpiceDB.
It seems like no matter what we do, we will increase tail latency. But the above statements are only true for a static maximum connection lifetime (the amount of time a connection is allowed to be used before being closed and replaced with a new one).
If we can increase the lifetime of a connection, then we can keep the connection acquisition rate stable against CockroachDB even when we increase the number of connections.
Previously, we capped our lifetimes at 5 minutes to deal with CockroachDB node drains. In order to increase beyond this limit, we will need to have some other strategy to avoid dropping traffic when a CockroachDB node is drained.
Handling CockroachDB SQL Query Failures
CockroachDB is a complex distributed system, and dealing with failure comes with the territory.
SQL queries can fail intermittently due to network problems, constrained system resources, and a slew of consistency-related reasons. For SpiceDB, the most common reason a query fails is because of routine maintenance of the CockroachDB Dedicated cluster—a query against a node that's down for a rolling update, for example.
The CockroachDB docs discuss how to handle retries on the client side, and they provide a library for retrying client-side retryable errors. But these are just for errors that Cockroach is able to tell the client need to be retried.
When a connection fails because a node is draining or unavailable, retrying the query naively doesn't work. Queries are retried on the same connection, which will be to the same gateway node, which in the case of a rolling update will remain unavailable for much longer than we're willing to wait to answer one query.
Our solution is to detect a much wider set of errors as retryable, and to retry them on a connection to a different node. We're able to do this because we can identify which gateway node a connection is using when we acquire it from the pool. When we hit a connection error, we can continue to ask the pool for a connection until it hands us one to a different node.
We can set lifetimes much longer than 5 minutes without dropping traffic because we can detect when a connection to a node has gone bad and retry on a different node. Longer lifetimes allow us to increase the number of connections against Cockroach without increasing tail latency since we are no longer forced to pack connection expiration into a five-minute window.
Detecting Cluster Changes with Long-Lived Connections
We can now balance the load across all CockroachDB nodes, and we can reduce the impact of connection latency on SpiceDB. We're done, right?
Not quite! There's one other issue that crops up if we allow for much longer connection lifetimes: the pool only knows what nodes exist by recording what it finds when it makes a new connection. If it’s not making new connections, it will fail to notice when new nodes are added (it will eventually, but only after enough connections have expired).
Our solution is to spin up a probe that periodically tries to connect to CockroachDB and records what nodes it finds. This adds minimal overhead to the CockroachDB cluster but gives SpiceDB much fresher information on what nodes exist to balance connections over.
With that in place, SpiceDB will notice when a Cockroach node is added and re-balance all of the connections in the pool until they're evenly split over the new set.
Sharing is Caring
All of the above work has been wrapped up in a new library, crdbpool, to make it available to the larger community. There's still plenty of work to be done and more optimizations we could explore.
We intentionally avoided solutions that require admin permission in CockroachDB. Admin users in CockroachDB Cloud can query directly for the full set of known nodes; crdbpool could take advantage of that if it detects that the user has admin permission or if that data is ever available to non-privileged users in the future. Or we could explore other sources of data entirely, like metrics.
If any of this sounds interesting and you'd like to help out (or give feedback), feel free to open an issue on the github repo and let us know.
Additional Reading
If you’re interested in learning more about Authorization and Google Zanzibar, we recommend reading the following posts:
- Understanding Google Zanzibar: A Comprehensive Overview
- A Primer on Modern Enterprise Authorization (AuthZ) Systems
- Fine-Grained Access Control: Can You Go Too Fine?
- Relationship Based Access Control (ReBAC): Using Graphs to Power your Authorization System
- Pitfalls of JWT Authorization
- crdbpool
- The One Crucial Difference Between Spanner and CockroachDB
- Getting Database Connection Draining Right
- CockroachDB 23.1 new defaults impact SpiceDB
- pgx