
At AuthZed, we are building a platform around SpiceDB - our open-source, ReBAC-based authorization system, inspired by the Zanzibar whitepaper. In the past, we have written about what Zanzibar is, why more businesses are adopting it, and some of the different ways you can implement relationship-based access control (ReBAC) in your own applications.
We have even published our own annotated copy of the Google Zanzibar whitepaper - to make it more accessible, add some outside perspective, and to help illuminate the Zanzibar model independent of Google and Google-scale problems.
But we have not spent much time talking about alternatives to Zanzibar and SpiceDB. Authorization is a field with a long and storied history, and there are several modern alternatives to Zanzibar that come with different trade-offs in terms of performance, deployment topology, and useability.
Understanding where SpiceDB fits in the landscape of authorization is important for anyone evaluating different solutions for authorization.
In this post, we are going to focus on one specific class of modern authorization technologies: policy-based access control (PBAC).
If you're not sure what PBAC is, how it differs from SpiceDB and Zanzibar, or when you should use one, the other, or both, then this post is for you.
What is Policy-Based Access Control?
A PBAC solution generally has at least two separate components:
- A policy engine, a software component that takes policy rules and data as input, and produces authorization decisions as output.
- A policy language, which is often a simple, declarative language for defining authorization rules.
Typically, these solutions also espouse a philosophy that the policies written in the policy language should be managed using standard software development lifecycle tools and techniques, though the degree to which that happens is up to the user.b
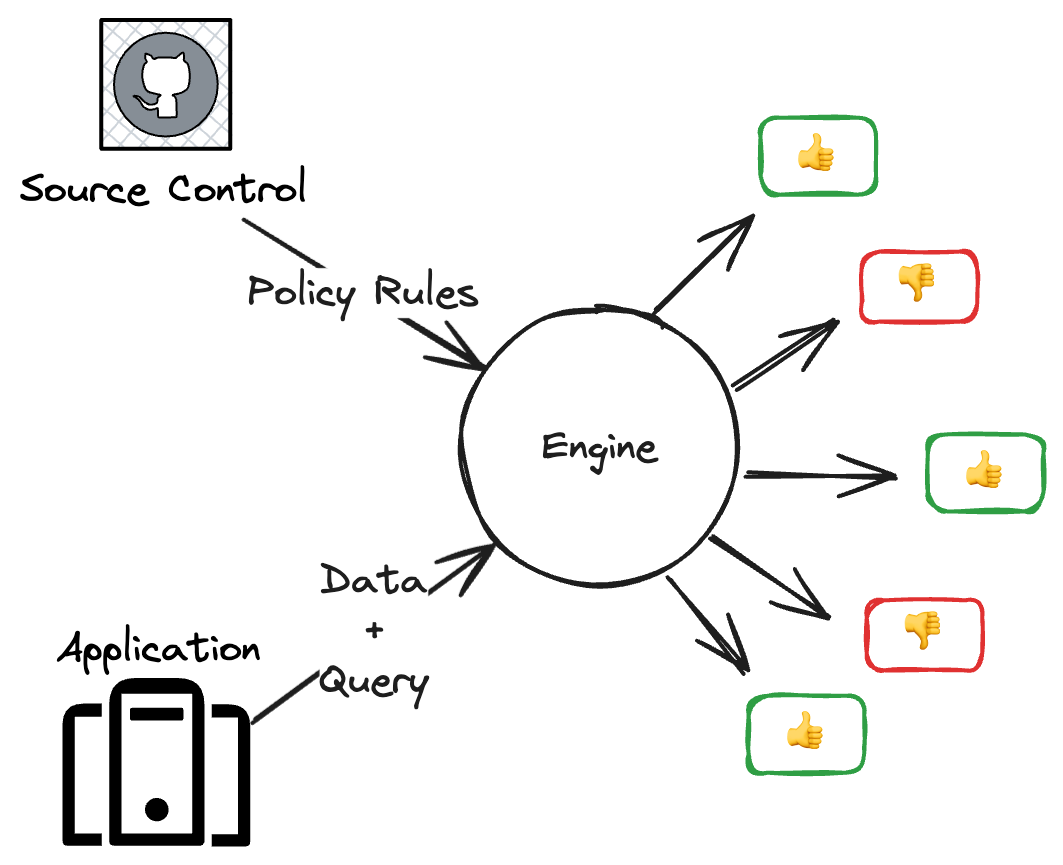
Though there are many ways to deploy a policy engine, they are usually deployed in one of three ways:
- Embedded directly into an application
- As a sidecar, serving queries over the local network
- As a reverse proxy or as an authorization step in a proxy, authorizing requests before sending them on to their destination.
Some examples of policy-based access control systems include:
- Styra's Open Policy Agent and Rego Language
- AWS's Verified Permissions and the Cedar language
- Hashicorp's Sentinal framework and language
Due to its ubiquity, we'll use OPA and Rego in the examples below. If the idea of using policies for authorization is totally new to you, it might be worth checking out what some of these projects have to say about themselves before reading on.
What is the difference between PBAC and Zanzibar-inspired ReBAC?
On the surface, ReBAC (Google Zanzibar) and SpiceDB may look very similar to PBAC:
- SpiceDB is an engine that computes authorization results over data.
- SpiceDB uses a declarative schema language that defines how permission is computed. Many teams choose to manage this schema with standard tools like
git.
But there are some major differences in how Zanzibar approaches access that sets it apart
Google Zanzibar is a Database
One of the defining features of Zanzibar is its use of a backing database to store authorization data and an explicit Write API for storing auth data for Zanzibar to use in later request evaluations.
At evaluation time, Zanzibar makes queries against the data in the database to evaluate authorization requests. This is what puts the "DB" in SpiceDB — in the Zanzibar model, authorization data must be explicitly written into the backing datastore ahead of query time, just like an RDBMS.
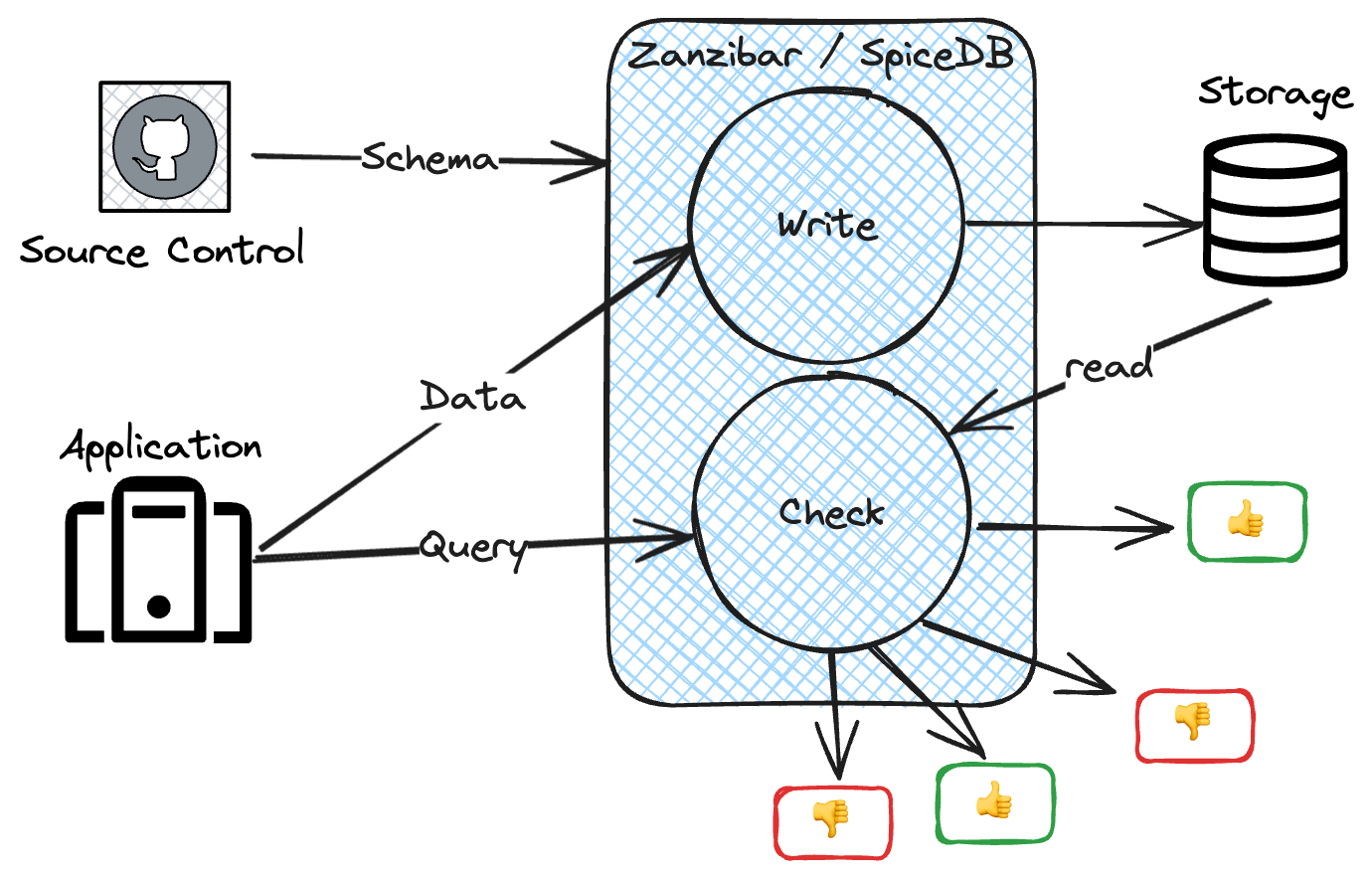
Google Zanzibar Stores Relationships
Most policy engines put very few restrictions on what authorization data can look like. Rego is a powerful and ergonomic datalog implementation that can be used as a general-purpose tool for computation over a set of facts stored as JSON.
In Google Zanzibar, all "facts" are relationship tuples: they define a relationship between a subject (user or group of users) and a resource.
The schema (or set of namespaces in Zanzibar parlance) defines how these base relationships relate to each other to form a graph.
A document is in a folder, a role grants access to a group, and a share grants a role access to a folder - these relationships form a graph that allows an application to ask a simple question like "Can Alice access the document?" by following the links in the graph.
Since everything is a graph, most authorization questions can fit into this model, including RBAC and ABAC.
Google Zanzibar Scales
Though policy engines generally require the user to send the data that the policy operates over alongside the authorization request, they sometimes offer other mechanisms for syncing relevant data down periodically, or pulling data at evaluation time, which could be used to get a similar approach to data as Google Zanzibar. And you could certainly choose to store data as relationships in a policy engine.
If you start to go down this road, though, it's good to be aware of the rest of the Zanzibar design, since it addresses things like consistency guarantees, hotspot caching, and general scaling strategies which don't generally have direct or simple answers in a policy engine.
When should you use a policy engine?
Policy engines are usually very fast at evaluating policies over small sets of local data. They do this very well, and a lot of time is invested in making the ergonomics developer-friendly.
Any time all of the data for a policy decision can be statelessly derived from a policy engine, they tend to shine. Here is an example of a great use of PBAC from OPA (playground):
package kubernetes.admission
import future.keywords
deny contains msg if {
input.request.kind.kind == "Pod"
some container in input.request.object.spec.containers
image := container.image
not startswith(image, "hooli.com/")
msg := sprintf("image '%s' comes from untrusted registry", [image])
}
Note that:
- The policy is not likely to update very often. A developer might need to add a new untrusted registry maybe once a year, if ever.
- Everything required to evaluate the policy is right there in the API request:
request.kind,input.request.object.spec.containers. - Because this is a Kubernetes example, the policy is likely running with Gatekeeper, which acts as an authorization hook for the kube-apiserver in the cluster. There are no edge deployments that need synchronization.
- The evaluation should be fast - the rules are simple and the data is small.
Many of the examples in the OPA playground are similar - they highlight the use of policy engines that are always fast and sensible to manage as code. But there is an entire section of the OPA docs dedicated to external data and the ways it can be fed into OPA policies for evaluation.
Most of these options require a connection to a database, or making networked API calls instead. Once you need to do one of these things, policy evaluation is no longer guaranteed to be fast.
Generally speaking, in 2023, and regardless of the particular stack, you can expect a local policy evaluation over a small local dataset to be on the order of microseconds. But even then, there can be cases where evaluation takes milliseconds.
Here's an excerpt from an OPA profile (source):
+----------+-------------+-------------+-------------+-------------+----------+----------+--------------+------------------+
| MIN | MAX | MEAN | 90% | 99% | NUM EVAL | NUM REDO | NUM GEN EXPR | LOCATION |
+----------+-------------+-------------+-------------+-------------+----------+----------+--------------+------------------+
| 43.875µs | 26.135469ms | 11.494512ms | 25.746215ms | 26.135469ms | 1 | 1 | 1 | data.rbac.allow |
+----------+-------------+-------------+-------------+-------------+----------+----------+--------------+------------------+
A p90 of 25ms means that even when the policy engine has all of the data it needs, it may not beat a network call to a nearby SpiceDB. And the time does not include the time it took to gather the data up to feed into the engine in the first place.
What follows is an example of an OPA policy that is not a great use for a policy engine (playground):
package kubernetes.validating.ingress
import future.keywords.contains
import future.keywords.if
deny contains msg if {
input_host := input.request.object.spec.rules[_].host
some other_ns, other_name
other_host := data.kubernetes.ingresses[other_ns][other_name].spec.rules[_].host
[input_ns, input_name] != [other_ns, other_name]
input_host == other_host
msg := sprintf("Ingress host conflicts with ingress %v/%v", [other_ns, other_name])
}
input_ns := input.request.object.metadata.namespace
input_name := input.request.object.metadata.name
is_ingress if {
input.request.kind.kind == "Ingress"
input.request.kind.group == "extensions"
input.request.kind.version == "v1beta1"
}
This is a more complex policy that ensures that no two Ingress Kubernetes objects try to bind to the same host name.
At first glance, it may not be clear what the issue is - it mostly comes down to this line:
other_host := data.kubernetes.ingresses[other_ns][other_name].spec.rules[_].host
This generates a list of all hosts referenced by other Ingress objects.
But where did this data come from?
It's left as an exercise to the reader, but the full list of all ingress objects needs to be queried first and provided to OPA at evaluation time.
This approach can work, but it removes the best property of policy engines: authorizing requests is no longer a fast process that runs at the edge, you have to deal with real networks and real databases in your authorization hotpath.
Once you need external data to answer authorization questions, you might start to wonder if your policy engine is the best tool for the job.
You got Policy in my ReBAC! You got ReBAC on my Policy!
SpiceDB is an open-source ReBAC-Based authorization system that strives to be a faithful Google Zanzibar implementation, deviating primarily when it seems best for usability or for de-Googling. One thing that we found, though, was that although Zanzibar was great for general authorization, there were often a few cases that users had that didn't lend themselves to relationship data stored ahead of time in SpiceDB.
This led us to develop Caveats, which uses CEL to conditionally define whether a relationship exists. Caveats offer some of the benefits of policy engines without sacrificing the benefits of Google Zanzibar and maintaining its caching and sharding strategies.
Using Caveats doesn't remove the need for a network roundtrip to SpiceDB. But it does mean you may not need to run a separate policy engine if you're already running SpiceDB, which can simplify your deployment.
What do we do at AuthZed?
We run a significant amount of infrastructure at AuthZed to power our Serverless and Dedicated products. In the end, we use a mix of different approaches:
- A dedicated SpiceDB instance powers the tenancy layer and permissions for the AuthZed Serverless platform.
- Although we don't use projects like Gatekeeper or Kyverno (at the moment), we do use some policy-like features of several Kubernetes projects to enforce standards in the clusters we run.
- The Fine Grained Access Management (FGAM) feature in SpiceDB Enterprise and SpiceDB Dedicated uses a hybrid approach: an embedded SpiceDB instance uses Caveats to evaluate requests at runtime, with no network roundtrips.
Whether or not you want to use policy-based access control, Google Zanzibar, or both, depends on the authorization problems you have. Hopefully, this post has helped distinguish when one approach may be better suited than the other.
Additional Reading
If you’re interested in learning more about Authorization and Google Zanzibar, we recommend reading the following posts: