

SpiceDB is the most comprehensive open source implementation of Google’s Zanzibar paper outside of Google itself. While the paper is very helpful for including not only the theoretical underpinnings of a relationship based access control system, but also many of the engineering learnings that come from running such a system with high availability and low-latency. The Zanzibar paper paints a vivid picture of how to combine the best concepts from distributed systems to create a reliable, performant system with no single points of failure that is also seemingly infinitely horizontally scalable. But the paper includes no code, no reference implementation, and no API definition files. This leaves would-be implementers with a set of really satisfying engineering challenges, where they know exactly where they are going, but with no map of how to get there.
In this week’s blog post, I will talk about how we’ve translated the major concepts of the Zanzibar paper into SpiceDB. I will lay out how the various internal interfaces are designed, implemented, and composed to create the service. You may find this article interesting if you’re learning about SpiceDB for professional reasons, looking to contribute to the project, or studying distributed systems or the Go programming language.
Let’s start by discussing the life of a request as it passes through SpiceDB.
The Life of a Request
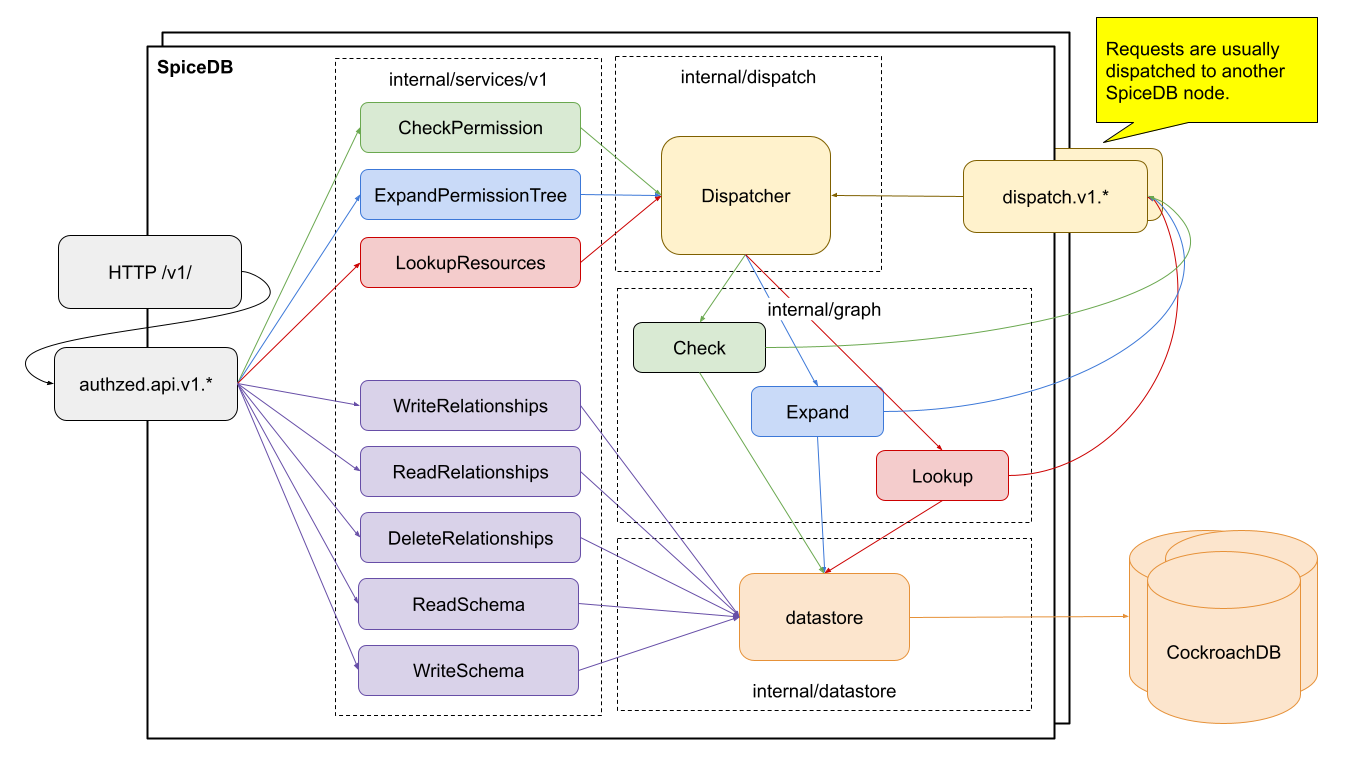
A request in SpiceDB goes through a few major phases.
- A request is received from the user.
- It is validated in a variety of ways.
- It is handled directly or passed off to another SpiceDB server for further handling.
We’ll start with receiving a request.
Receiving a Request
SpiceDB is fundamentally a gRPC service. This gives us a few really nice properties out of the box: HTTP/2 request pipelining, support for streaming responses, and a typed interface definition language that compiles to efficient payloads. gRPC requests are sent over the wire as protocol buffers, an efficient, flexible binary representation of structured data that is used widely at Google and other major projects. Our gRPC API defines the main entry points and request objects that are constructed by users and our client libraries. gRPC itself handles decoding the binary request objects, and passing them off to handlers running in goroutines, a type of lightweight thread in Go.
While gRPC is our preferred method of receiving requests, some users operate in environments in which HTTP/2 or binary payloads are unsupported. At the request of those users, SpiceDB is also capable of running an HTTP gateway that will translate requests from HTTP1+json into gRPC requests on their behalf. This code can be found in the internal/gateway package.
Once the gRPC request has been decoded it is sent through a chain of gRPC middlewares for validation.
Request Validation
The first part of validating a request is performed by protobuf itself! Thanks to the structured and typed nature of a protobuf message, many malformed requests will never make it through the gRPC processing layer. For example, a message that attempts to send a string where we expect an integer will fail to unmarshal and an error will be sent to the user without us having to do a thing.
The next step for validating a request is simple semantic validation. While protobuf ensures that we receive an integer where we expect an integer, how do we know that a given integer makes sense in our application? Another example: in proto3, the most recent version of the protobuf spec, all fields are considered optional, but our application often requires that certain fields be supplied for the request to be valid. For this type of simple semantic validation we use a plugin called protoc-gen-validate, which allows us to annotate our API definitions with some simple semantic rules that are enforced on each request. The actual enforcement of these rules is done by a gRPC middleware called validator.
The final form of request validation is data-driven semantic validation. This type of validation is usually dependent on the specific request as applied to the data stored in SpiceDB. This validation can be found sprinkled throughout the SpiceDB code, usually in the form of errors that are raised by individual pieces of code, usually the request handlers, that have the necessary context to determine that the request is in-fact, invalid. Let’s take a look at these request handlers now.
Handling Requests
The gRPC API defines eight (as of the time of writing) top level methods. Three are simple CRUD operations against relationships: WriteRelationships, ReadRelationships, and DeleteRelationships. Two deal with CRUD operations on schema: ReadSchema and WriteSchema. The final three are more complicated permissions operations that interpret relationships under the context of a schema: CheckPermission, ExpandPermission, and LookupResources.
Relationship CRUD requests are the simplest to handle. These requests are specific actions the user wishes us to take against the relationships data stored in the datastore. These simple requests are translated into specific datastore operations, executed directly, and the results are passed back to the user.
Schema CRUD requests are slightly more complicated. You can think of them like DDL operations on relational databases: they define which types of relationships can be specified and how they are interpreted. Because of their nature in defining structure in SpiceDB, they go through much more rigorous data-driven semantic validation before requests are accepted. Ultimately though, these also are repackaged as datastore operations and persisted in durable storage.
The final and most interesting type of operation (and arguably the reason SpiceDB needs to exist at all!) is the one that brings schema and relationships together to form permissions! You can read more about how permissions are actually computed in Joey’s “Check it out” blog post. The Zanzibar paper talks about breaking up problems into sub-problems and sending them on to other servers for processing, and then caching the results at every layer. In SpiceDB, we call this process “dispatch”, and it is a large part of what makes SpiceDB so powerful.
Let’s take a look at how dispatch works.
Dispatch
In my Zanzibar talk for Papers We Love NYC you can learn more about how we break down user generated permissions requests into a set of individually cacheable sub-problems. SpiceDB uses various implementations of the dispatch interface to handle the following:
- Breaking down a permissions request into multiple sub-requests
- Caching the responses to sub-requests
- Sending sub-requests to another SpiceDB instance that is likely to have the answer cached
- Directly handling the smallest possible “leaf” sub-requests
The interface itself is very simple:
type Dispatcher interface {
Check
Expand
Lookup
// Close closes the dispatcher.
Close() error
}
// Check interface describes just the methods required to dispatch check requests.
type Check interface {
// DispatchCheck submits a single check request and returns its result.
DispatchCheck(ctx context.Context, req *v1.DispatchCheckRequest) (*v1.DispatchCheckResponse, error)
}
// Expand interface describes just the methods required to dispatch expand requests.
type Expand interface {
// DispatchExpand submits a single expand request and returns its result.
DispatchExpand(ctx context.Context, req *v1.DispatchExpandRequest) (*v1.DispatchExpandResponse, error)
}
// Lookup interface describes just the methods required to dispatch lookup requests.
type Lookup interface {
// DispatchLookup submits a single lookup request and returns its result.
DispatchLookup(ctx context.Context, req *v1.DispatchLookupRequest) (*v1.DispatchLookupResponse, error)
}
The datatypes are supplied by the dispatch gRPC service which we used when serializing and sending requests to other SpiceDB instances
You’ll recall that we referred to calculating permissions as interpreting relationships under the context of a schema. Let’s see how this works in practice.
Graph Requests
In Joey’s Check it out post, he details how we transform relationships and schema into a directed graph, and then use this directed graph to answer questions about permissions. While the exact transformation process is outside of the scope of this post, the code that supports it often uses the word “graph” to represent this association. Specifically, there is an entire package, internal/graph, that is responsible for traversing this graph of schema and relationships, and either calculating answers directly, or breaking the request down into sub-requests and sending those off.
A trivial implementation of the dispatch interface in the internal/dispatch/graph package is responsible for connecting requests and sub-requests to this core computation logic. Whenever this graph processor discovers a cacheable sub-problem, it sends it off to another implementation of the dispatch interface, which will eventually return an answer. If the request is being sent off to another node, that happens through a remote implementation of the dispatch API.
Remote Dispatch
Often requests will be broken down into sub-requests, and those will be sent to another SpiceDB server for handling. There are two reasons we do this. First, by utilizing a larger number of servers we can parallelize the process. This can have performance benefits when coupled with a sufficiently fast network and compute infrastructure. The more important reason to distribute sub-problems is that we want to send the request off to a SpiceDB server that already has the answer cached.
Each SpiceDB instance contains a cache of the recent answers that it has computed for (sub-)requests, and can serve these answers out of cache directly. By using a consistent-hash to always send the same (sub-)requests to the same server, we can achieve very high cache hit rates.
SpiceDB uses an internal dispatch gRPC service and a client with a consistent hash based load-balancing policy for always sending (sub-)requests to the same backend, which will naturally build up a cache of relevant responses.
The last piece of dispatch that we will talk about is caching.
Caching Dispatch
We’re already using the dispatch interface for both handling requests directly, and for sending off sub-requests. This allows us to use a single additional caching implementation of the dispatch interface for both client-side and server-side caching!
The caching dispatcher will:
- Transform an incoming request into a stable cache-key
- Return valid results for that cache-key that it may find locally
- Delegate that requests to another dispatch object if not in cache
- Cache successful responses under the stable cache-key for further use
If we use the caching dispatcher between the server handlers and the graph dispatcher, it becomes a server-side cache. If we use it between the graph dispatcher and a remote dispatcher, it becomes a client-side cache.
Now that we have explored the dispatch interface, let’s talk about how relationship data actually gets persisted.
The Datastore
SpiceDB has a datastore interface, a set of datastore implementation conformance tests, and a few existing implementations. The interface is used to read and write both relationship and schema data to a storage layer from which it can be retrieved. The only operations permitted on the datastore are basic CRUD operations, and operations relating to the causal ordering of those CRUD operations.
Causal ordering and snapshot reads are used to prevent the “New Enemy” problem, which is explored in-depth in that post. This requirement on datastore implementations comprises the bulk of the complexity for each implementation. Some implementations, such as CockroachDB, can delegate this responsibility to their backing datastore. Other implementations, such as PostgreSQL, and the ephemeral in-memory database, must track their own causal ordering and snapshots by manually implementing multi-version concurrency control.
Not all datastore implementations have the same performance characteristics. In the “Selecting a Datastore” docs article you can find more information about existing implementations. There is currently a proposal to improve the datastore interface. If you are considering implementing another datastore backend, I highly encourage you to make your voice heard on the proposal or in our Zanzibar Discord Server.
Proxy Implementations
There are a few implementations of the datastore that just wrap existing datastore implementations to extend or in some cases restrict their functionality. There are currently three proxy datastore implementations:
- The hedging proxy will issue a request to a downstream datastore, and if it doesn’t get a response back before the request is considered statistically slow, it will issue another request to the downstream datastore and use whichever response comes back first.
- The readonly proxy will transparently pass read operations to the downstream datastore, but will immediately return an error to any write operations.
- The mapping proxy takes a mapper object, which can translate object type names to an encoded version, which can be used to provide a datastore-level tenant isolation mechanism.
These proxy implementations are designed to work with any conformant datastore.
Putting It All Together
I hope this has been a helpful introduction to the code and architecture behind SpiceDB. The cmd/spicedb/serve.go file is where all of these components get wired up together to form the main SpiceDB service. Our Zanzibar Discord Server is the best place to come chat with the team behind SpiceDB, and others who are currently on the journey to transforming their permissions. If you love working on these types of things, you can apply to work at Authzed, or you can start contributing to the open source right away!
Additional Reading
If you’re interested in learning more about Authorization and Google Zanzibar, we recommend reading the following posts:
