
Why This Guide Exists
SpiceDB load tests will prove that SpiceDB can meet your performance targets. SpiceDB load tests can also determine how much hardware it will take to meet your performance targets.
The performance characteristics of SpiceDB are nuanced, and there are many important considerations to keep in mind when performing a realistic load test. This guide will help you understand the performance basics of SpiceDB and will give you suggestions for building a realistic load test.
Seeding Your Data
The Performance Impacts of Relationship Data Distribution
The cardinality of your relationships (how many or how few objects are related to another object) significantly impacts the computational cost of CheckPermission and Lookup requests. Because of this, it’s essential to seed relationships for your load test that relate objects together in a way that resembles real-world conditions.
Example
The below schema, relationships, and CheckPermission request are an example of how relationship cardinality can affect performance.
Schema:

Relationships:

Check permission request:
CheckPermissionRequest {
resource: ObjectReference {
object_type: 'document'
object_id: 'somedocument'
}
permission: 'view'
subject: SubjectReference{
object: ObjectReference {
object_type: 'user'
object_id: 'evan'
}
}
}
CheckPermission computations in SpiceDB are broken into subproblems. The more subproblems SpiceDB has to compute, the more time it will take SpiceDB to issue a response to a CheckPermission request. Increased relationship cardinality often means that SpiceDB will need to compute more subproblems.
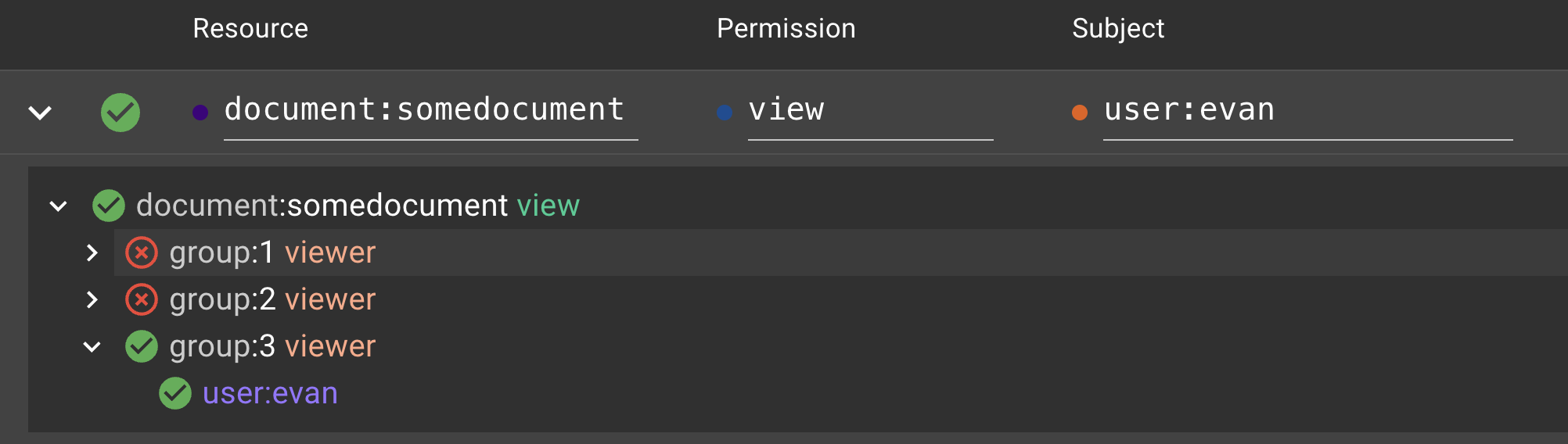
If the above CheckPermissionRequest occurred on the above schema and set of relationships, SpiceDB had to compute the answer to three subproblems in order to determine if evan has view permission on somedocument. The subproblems are:
- Is
evanrelated togroup 1as aviewer? - Is
evanrelated togroup 2as aviewer? - Is
evanrelated togroup 3as aviewer?
You can see these subproblems in a “check watch” on the SpiceDB playground. Here is a playground link to our example.
Here is an illustration of how SpiceDB walks the graph in our example:
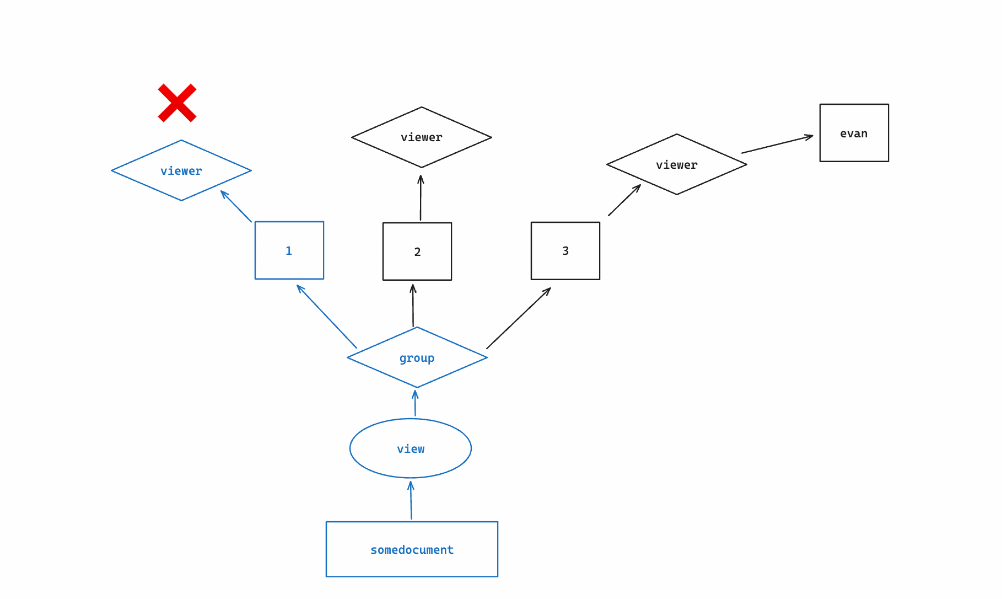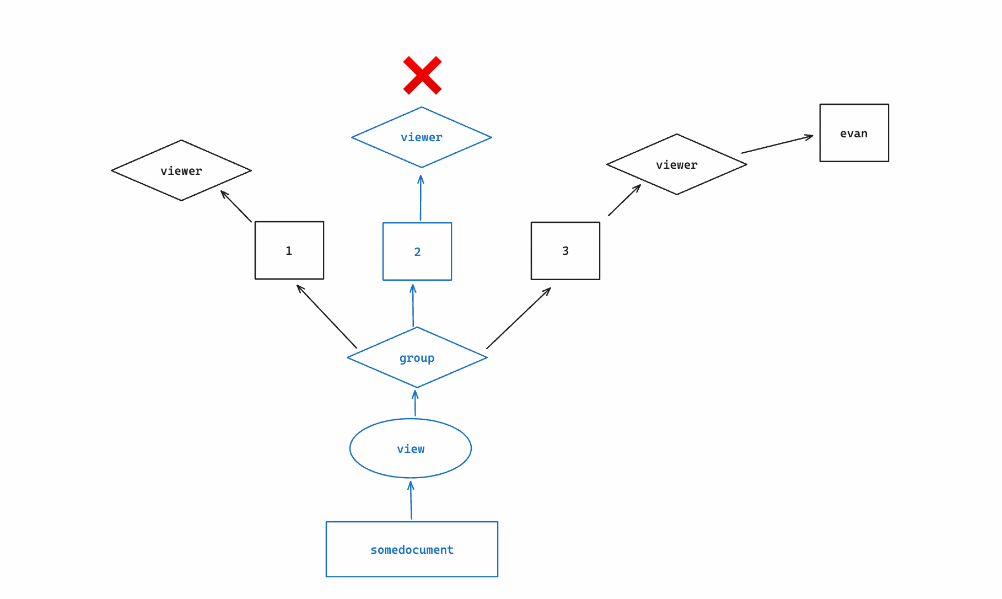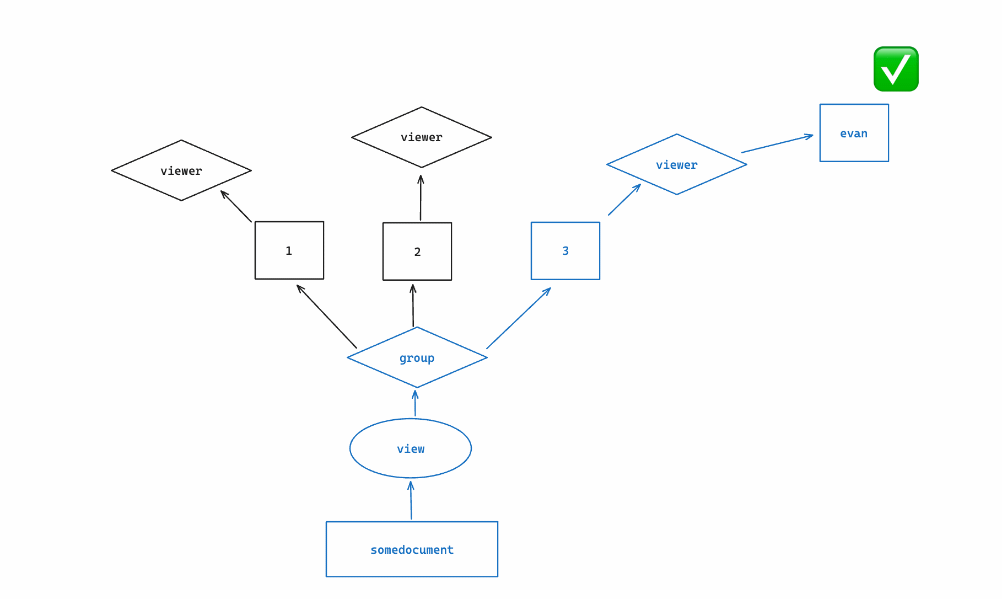
The concept of computing subproblems for intermediary objects, like we did for groups, is referred to as “fanning out” or “fanout”. If more groups were related, to somedocument, it’s likely that more subproblems will be calculated to determine view permission; however, the query will stop calculating subproblems (”short circuit”) if it positively satisfies the permission check before all paths are exhausted (intersections & and exclusions - are the exception to this).
While fanout is almost always unavoidable, fanout can result in an exponential increase to the the number of subproblems that must be computed, therefore, when performing a load test it’s critical to make requests to a SpiceDB instance that is seeded with relationship data that closely mimics real world data.
Identifying your Relationship Distribution Patterns for a Load Test
After reading the above section, you should have an understanding of why relationship data distribution matters. This section offers tips for getting the relationship distribution correct when seeding relationship data for a load test. Here are some helpful tips (these tips assume you already have a schema finalized):
- Generate a list of object types and their relationships. In the example above we have two:
document#group@groupandgroup#viewer@user. - Identify how many objects of each type exist. In our scenario, we’ll need to determine how many objects of type
document,group, anduserexist. - If a resource object has multiple relations defined on it, decide what percentage of resource objects have a relationship defined with the first relation, what percentage of resource objects will have a relationship defined with the second relation, and so on. Keep in mind that it’s possible for resource objects to have relationships written from multiple relations. (e.g. a single resource object can have a relationship(s) written for both the first and second relation)
- Identify the distribution of the relationships for specific relations. You’ll need to identify what percentage of the resource objects relate to what percentage of the subject objects through a specific relation. If you can’t identify the distribution of your relationships for specific relations, we recommend using a Pareto distribution as an approximation. (e.g. 80% of
documentobjects are related to 20% ofgroupobjects through thegrouprelation) - Codify it! Now that you’ve completed the thought exercise, you’ll need to codify this information in relationship generating code.
Don’t hesitate to reach out to the Authzed team. We recommend that you pre-seed your relationships data before a load test. Writes during a load test should be used for testing write performance. Writes during a load test should not be used for seeding data that will be used by CheckPermission and LookUp requests.) if you have any questions or need help thinking through your data distribution.
Checks
The specific resources, permissions, and subjects that are checked in a CheckPermission request can have a significant impact on SpiceDB performance.
Understanding the Performance Impacts of the Distribution of Checks
Cache Utilization
Every time a SpiceDB subproblem is computed, it is cached for the remainder of the current quantization interval window (5s by default). Subsequent requests (checks or lookups) that use the same revision and require a subset of the cached subproblems can fetch the pre-computed subproblems from an in memory cache instead of fetching the subproblem data from the datastore and computing the subproblem. Therefore, every time a cached SpiceDB sub-problem is used, computation is avoided, load on the datastore is avoided, and a roundtrip to the datastore is avoided. You can read about cache configurations in the "Configuration" section below.
Fanout Impact
In the “The Performance Impacts of Relationship Data Distribution” section, fanout was discussed. Certain CheckPermission requests will require more fanout to compute a response; therefore, it’s important to spread your checks out across a realistic sample of subjects, resources, and permissions.
Realistic Sample Size
Will your entire user base be online at the same time? Probably not. Therefore, you should only issue CheckPermission request for a subset of your user base. This subset should represent the largest number of users online at a given time. Choosing a percentage of your users will help simulate a more accurate cache hit ratio.
Performance Impact of Negative Checks
Negative checks (checks that return PERMISSIONSHIP_NO_PERMISSION) are almost always more computationally expensive than positive checks because negative checks will walk every branch of the graph while searching in vain for a satisfactory answer. For most SpiceDB deployments, a significant majority of checks are positive.
Identifying Your CheckPermission Distribution Patterns for a Load Test
These steps will help you design a realistic CheckPermission Request distribution:
- As mentioned in the “Realistic Sample Size” section above, determine what percentage of users will be online at a given time and only check that subset of your user base.
- It’s important that you pick a subset of users and resources that are a representative distribution of real world checks. e.g. don’t just check a subset of users that have access to a lot of resources. Check users that have access to a representative amount of resources. Some users may have access to many resources, some users may have access to few resources.
- Identify distributions for particular object types. If you can’t determine your distributions, you may want to use a Pareto distribution as an approximation e.g. 20% of a particular resource type accounts for 80% of the checks or 20% of the users account for 80% of the checks.
Lookups
Understanding the Performance Impacts of Lookups
Almost always, Lookups are more computationally expensive than checks. To put it simply, more subproblems need to be calculated to answer lookups compared to checks. Lookups that traverse intersections and exclusions are more expensive than lookups that do not. Lookups can both use the cache and populate the cache with subproblems from and for checks.
Identifying Your Lookup Patterns
Lookup Subjects
Identify your distribution of Lookups. e.g. 20% of resource objects will account for 80% of lookups or permission x will account for 90% of lookups and permission y will account for 10% of lookups. You should be thoughtful about how you distribute your LS requests among your users as some user’s will have more computationally expensive LS requests than others.
Lookup Resources
Identify a subset of your user base that will be online at a given time and only perform LR requests for those users in your test. You should be thoughtful about how you distribute your LR requests among your users as some user’s will have more computationally expensive LR requests than others.
Writes
Understanding the Performance Impacts of Writes
Writes impact datastore performance far more than they impact SpiceDB node performance.
CockroachDB
If you’re using CockroachDB there are special performance considerations to understand.
TOUCH vs CREATE on Postgres
On Postgres, CREATE is more performant than TOUCH. TOUCH always performs a delete and then an insert while CREATE just performs an insert and throws an error if the data already exists.
Identifying Your Write Patterns
We recommend that you pre-seed your relationships data before a load test. Writes during a load test should be used for testing write performance. Writes during a load test should not be used for seeding data that will be used by CheckPermission and Lookup requests.
Writes should be a part of every thorough load test. When designing your load tests, we recommend you quantify your writes in one of two ways:
- As a percentage of overall requests i.e .5% of requests are writes
- As a number of writes per second i.e. 30 writes per second
In most circumstances, the resource, subject, and permission of the relationships you write will have no impact on performance.
Schema Considerations
Performance should not be a primary concern when you are modeling your schema. We recommend that you first model your schema to satisfy your business requirements. After your business requirements have been satisfied by your schema, you can examine the following points to see if there is any room for optimization.
We highly recommend that you get in touch with the Authzed team for a schema review session before performing a load test.
Caveats
In general, we only recommend using caveats when when you’re evaluating dynamic data. (e.g. users can only access the document between 9-5 or users can only access the document when you are in the EU) Almost all other scenarios can be represented in the graph. Caveats add computational cost to checks because their evaluations can’t be cached.
Nesting and Recursion
If SpiceDB has to walk more hops on the graph, it will have to compute more subproblems. For example, recursively relating folder objects two layers deep will not incur much of a performance penalty by itself. Recursively relating folder objects 30 layers deep is likely to incur a performance penalty. The same can be said by nesting objects of different object definitions 30 layers deep.
Intersections and Exclusions
Intersections and exclusions can have a small negative impact on Check performance because they force SpiceDB to look for “permissionship” on both sides of the intersection or exclusion.
Intersections and exclusions can have a significant negative performance Impact on LookupResources because they require SpiceDB to compute a candidate set of subjects to the left of the intersection or exclusion and then to perform a check on all candidates in the set.
Configuration
There are certain SpiceDB configuration settings and request parameters that should be considered before a load test.
Quantization
The SpiceDB quantization interval setting is used to specify the window of time in which we should use a chosen revision of SpiceDB’s datastore data. Effectively, the datastore-revision-quantization-interval determines how long cached results will live. There is also the datastore-revision-quantization-max-staleness-percent setting. The datastore-revision-quantization-max-staleness-percent specifies the percentage of the revision quantization interval where we may opt to select a stale revision for performance reasons. Increasing both or either numbers is likely to increase cache utilization which will lead to better performance. I recommend this article for more information on the staleness and performance implications of quantization.
Consistency
Consistency has a significant effect on cache utilization and thus performance. Cache utilization is specified on a per request basis. Before conducting a load test, it’s important you understand the performance and staleness implications of the consistency message(s) you are using. The majority of SpiceDB users are using minimize_latency for every request. The Authzed team almost always recommends against fully_consistent, in lieu of fully_consistent we recommend using at_least_as_fresh so that you can utilize the cache when it’s safe to do so. You can read more about consistency here.
Load Generation Tooling
We have an open-source load generator called Thumper. We recommend you build your load tests with Thumper. Thumper allows you to distribute checks, lookups, and writes as you see fit. Thumper has been engineered by the Authzed team to provide a realistic and even flow of requests. If you use Thumper, it will be easier for the Authzed team to understand your load test and help you make adjustments.
You can find the source code for Thumper on Github, and there is usage documentation on our docs site. Pre-built images are available on DockerHub and on Quay.io, and you can download binaries on the Releases page.
Monitoring
SpiceDB metrics can help you 1) ensure you’re generating the correct number of requests per second, 2) give you information on request latency, and 3) help you fine tune your load test. The easiest way to consume and view metrics is via the SpiceDB Dedicated Management Console. There the metrics are preconfigured for you. If you’re self hosting SpiceDB (not recommended for a load test) you can export metrics via the SpiceDB Prometheus endpoint.
Scaling Hardware
Datastore
When operating a SpiceDB cluster you must keep in mind the underlying DB. By far, the most common sign you need to scale your datastore up or out is high datastore CPU utilization.
SpiceDB Compute
Like the datastore, it’s important to scale if CPU utilization is high; however, since SpiceDB is such a performance sensitive workload, we’ve seen significant performance gains from scaling out CPU in nodes that we’re experiencing less than 30% CPU utilization.
How Authzed can Help You With Your Load Test
The Authzed team has experience running massive SpiceDB load tests and we want to help you with your load test too. Here’s a few examples of how we can help:
- Review your schema to make sure it’s fully optimized
- Review or help you create scripts to seed your relationship data
- Review or help you create scripts to generate CheckPermission and Lookup traffic
- Provide you a trial of SpiceDB Dedicated, our private SaaS offering
- During the trial, we can help you make adjustments and optimizations
- If you decide to move forward with SpiceDB Dedicated after the trial, you can keep using your trial cluster that we fine-tuned and right sized with you during the trial
- If you decide to self host SpiceDB Enterprise after the trial, we’ll provide you a write up of all of the optimizations we made during the trial and the amount of hardware we used so you can deploy a SpiceDB cluster that has been optimized for your workload into your environment
If you’d like to schedule some time for a consultation from the Authzed team, please do so here.